
 | ||
A load-balanced switch is a switch architecture which guarantees 100% throughput with no central arbitration at all, at the cost of sending each packet across the crossbar twice. Load-balanced switches are a subject of research for large routers scaled past the point of practical central arbitration.
Contents
Introduction
Internet routers are typically built using line cards connected with a switch. Routers supporting moderate total bandwidth may use a bus as their switch, but high bandwidth routers typically use some sort of crossbar interconnection. In a crossbar, each output connects to one input, so that information can flow through every output simultaneously. Crossbars used for packet switching are typically reconfigured tens of millions of times per second. The schedule of these configurations is determined by a central arbiter, for example a Wavefront arbiter, in response to requests by the line cards to send information to one another.
Perfect arbitration would result in throughput limited only by the maximum throughput of each crossbar input or output. For example, if all traffic coming into line cards A and B is destined for line card C, then the maximum traffic that cards A and B can process together is limited by C. Perfect arbitration has been shown to require massive amounts of computation, that scales up much faster than the number of ports on the crossbar. Practical systems use imperfect arbitration heuristics (such as iSLIP) that can be computed in reasonable amounts of time.
A load-balanced switch is not related to a load balancing switch, which refers to a kind of router used as a front end to a farm of web servers to spread requests to a single website across many servers.
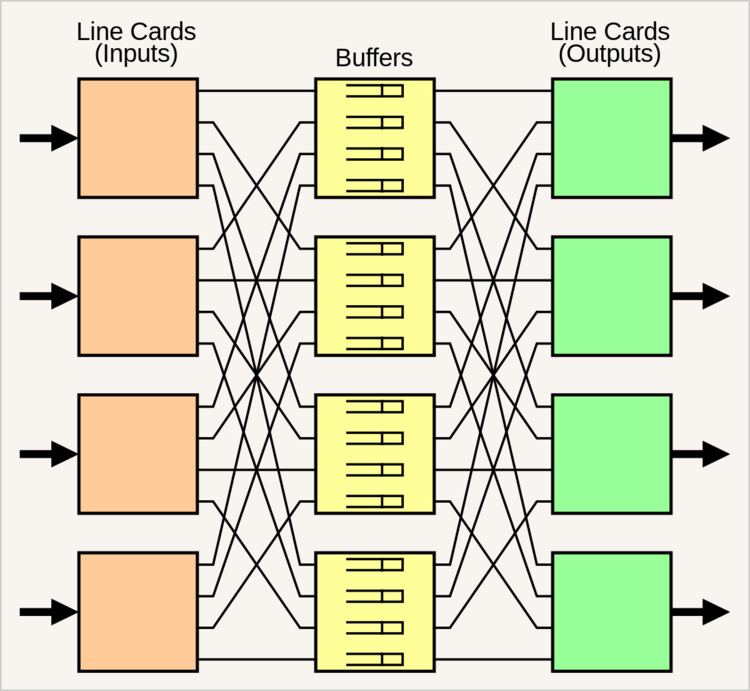
Basic architecture
As shown in the figure to the right, a load-balanced switch has N input line cards, each of rate R, each connected to N buffers by a link of rate R/N. Those buffers are in turn each connected to N output line cards, each of rate R, by links of rate R/N. The buffers in the center are partitioned into N virtual output queues.
Each input line card spreads its packets evenly to the N buffers, something it can clearly do without contention. Each buffer writes these packets into a single buffer-local memory at a combined rate of R. Simultaneously, each buffer sends packets at the head of each virtual output queue to each output line card, again at rate R/N to each card. The output line card can clearly forward these packets out the line with no contention.
Each buffer in a load-balanced switch acts as a shared-memory switch, and a load-balanced switch is essentially a way to scale up a shared-memory switch, at the cost of additional latency associated with forwarding packets at rate R/N twice.
The Stanford group investigating load-balanced switches is concentrating on implementations where the number of buffers is equal to the number of line cards. One buffer is placed on each line cards, and the two interconnection meshes are actually the same mesh, supplying rate 2R/N between every pair of line cards. But the basic load-balanced switch architecture does not require that the buffers be placed on the line cards, or that there be the same number of buffers and line cards.
One interesting property of a load-balanced switch is that, although the mesh connecting line cards to buffers is required to connect every line card to every buffer, there is no requirement that the mesh act as a non-blocking crossbar, nor that the connections be responsive to any traffic pattern. Such a connection is far simpler than a centrally arbitrated crossbar.
Keeping packets in-order
If two packets destined for the same output arrive back-to-back at one line card, they will be spread to two different buffers, which could have two different occupancies, and so the packets could be reordered by the time they are delivered to the output. Although reordering is legal, it is typically undesirable because TCP does not perform well with reordered packets.
By adding yet more latency and buffering, the load-balanced switch can maintain packet order within flows using only local information. One such algorithm is FOFF (Fully Ordered Frames First). FOFF has the additional benefits of removing any vulnerability to pathological traffic patterns, and providing a mechanism for implementing priorities.
Single chip crossbar plus load-balancing arbiter
The Stanford University Tiny Tera project (see Abrizio) introduced a switch architecture that required at least two chip designs for the switching fabric itself (the crossbar slice and the arbiter). Upgrading the arbiter to include load-balancing and combining these devices could have reliability, cost and throughput advantages.
Single global router
Since the line cards in a load-balanced switch do not need to be physically near one another, one possible implementation is to use an entire continent- or global-sized backbone network as the interconnection mesh, and core routers as the "line cards". Such an implementation suffers from having all latencies increased to twice the worst-case transmission latency. But it has a number of intriguing advantages: