
 | ||
Learning automata is one type of Machine Learning algorithm studied since 1970s. Compared to other learning scheme, a branch of the theory of adaptive control is devoted to learning automata surveyed by Narendra and Thathachar (1974) which were originally described explicitly as finite state automata. Learning automata select their current action based on past experiences from the environment. It will fall into the range of reinforcement learning if the environment is stochastic and Markov Decision Process (MDP is used).
Contents
History
Research in learning automata can be traced back to the work of Tsetlin in the early 1960s in the Soviet Union. Together with some colleagues, he published a collection of papers on how to use matrices to describe automata functions. Additionally, Tsetlin worked on reasonable and collective automata behaviour, and on automata games. Learning automata were also investigated by researches in the United States in the 1960s. However, the term learning automaton was not used until Narendra and Thathachar introduced it in a survey paper in 1974.
Definition
A learning automaton is an adaptive decision-making unit situated in a random environment that learns the optimal action through repeated interactions with its environment. The actions are chosen according to a specific probability distribution which is updated based on the environment response the automaton obtains by performing a particular action.
With respect to the field of reinforcement learning, learning automata are characterized as policy iterators. In contrast to other reinforcement learners, policy iterators directly manipulate the policy π. Another example for policy iterators are evolutionary algorithms.
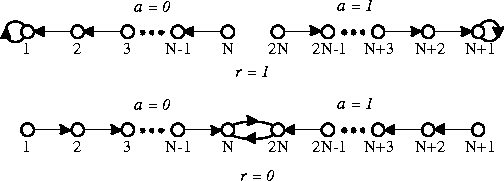
Formally, Narendra and Thathachar define a stochastic automaton to consist of:
In their paper, they investigate only stochastic automata with r=s and G being bijective, allowing them to confuse actions and states. The states of such an automaton correspond to the states of a "discrete-state discrete-parameter Markov process". At each time step t=0,1,2,3,..., the automaton reads an input from its environment, updates p(t) to p(t+1) by A, randomly chooses a successor state according to the probabilities p(t+1) and outputs the corresponding action. The automaton's environment, in turn, reads the action and sends the next input to the automaton. Frequently, the input set x = { 0,1 } is used, with 0 and 1 corresponding to a nonpenalty and a penalty response of the environment, respectively; in this case, the automaton should learn to minimize the number of penalty responses, and the feedback loop of automaton and environment is called a "P-model". More generally, a "Q-model" allows an arbitrary finite input set x, and an "S-model" uses the interval [0,1] of real numbers as x.
Finite action-set learning automata
Finite action-set learning automata (FALA) are a class of learning automata for which the number of possible actions is finite or, in more mathematical terms, for which the size of the action-set is finite.