
 | ||
LIRS (Low Inter-reference Recency Set) is a page replacement algorithm with an improved performance over LRU (Least Recently Used) and many other newer replacement algorithms. This is achieved by using reuse distance as a metric for dynamically ranking accessed pages to make a replacement decision. The algorithm was developed by Song Jiang and Xiaodong Zhang.
Contents
Quantifying the locality
While all page replacement algorithms rely on existence of reference locality to function, a major difference among different replacement algorithms is on how this locality is qualified. LIRS uses reuse distance of a page, or the number of distinct pages accessed between two consecutive references of the page, to quantify locality. Specifically, LIRS uses last and second-to-last references (if any) for this purpose. If a page is accessed for the first time, its reuse distance is infinite. In contrast, LRU uses recency of a page, which is the number of distinctive pages accessed after the reference of the page, to quantify locality. To take into account of up-to-date access history, the implementation of LIRS actually uses the larger of reuse distance and recency of a page as the metric to quantify its locality, denoted as RD-R. Assuming the cache has a capacity of C pages, the LIRS algorithm is to rank recently accessed pages according to their RD-R values and retain the C most highly ranked pages in the cache.
The concepts of reuse distance and recency can be visualized as below, in which T1 and T2 are page B’s second-to-last and last reference times, respectively, and T3 is the current time.
. . . B . . . B . . . . . . . . . . B . . . . . ^----Reuse Distance---^--Recency--^ T1 T2 T3Selecting the replacement victim
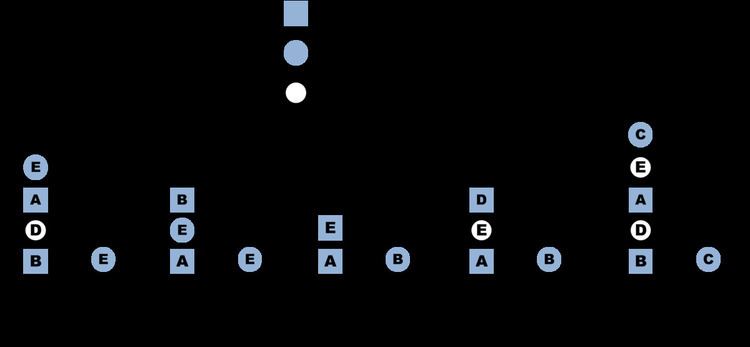
LIRS organizes metadata of cached pages and some uncached pages and conducts its replacement operations described as below, which are also illustrated with an example in the graph.
- The cache is divided into a Low Inter-reference Recency (LIR) and a High Inter-reference Recency (HIR) partition. The LIR partition is to store the most highly ranked pages (LIR pages) and the HIR partition is to store some of the other pages (HIR pages).
- The LIR partition holds the majority of the cache, and all LIR pages are resident in the cache.
- All recently accessed pages are placed in a FIFO queue called the LIRS stack (stack S in the graph), and all resident HIR pages are also placed in another FIFO queue (stack Q in the graph).
- An accessed page is moved to the top of Stack S and any HIR pages at the stack’s bottom are removed. For example, Graph (b) is produced after page B is accessed on Graph (a).
- When a HIR page in Stack S is accessed, it turns into a LIR page and accordingly the LIR page currently at Stack S’s bottom turns into a HIR page and moves to the top of Stack Q. For example, Graph (c) is produced after page E is accessed on Graph (a).
- When there is a miss and a resident page has to be replaced, the resident HIR page at the bottom of Stack Q is selected as the victim for replacement. For example, Graphs (d) and (e) are produced after pages D and C are accessed on Graph (a), respectively.
Deployment
LIRS has been deployed in MySQL since version 5.1. It is also adopted in Infinispan data grid platform. An approximation of LIRS, CLOCK-Pro, is adopted in NetBSD.