
Latest release 2 | Website jbig2.com | |
 | ||
Contained by Portable Document Format, FAX Standard ITU T.88 & ISO/IEC 14492 | ||
JBIG2 is an image compression standard for bi-level images, developed by the Joint Bi-level Image Experts Group. It is suitable for both lossless and lossy compression. According to a press release from the Group, in its lossless mode JBIG2 typically generates files 3–5 times smaller than Fax Group 4 and 2–4 times smaller then JBIG, the previous bi-level compression standard released by the Group. JBIG2 has been published in 2000 as the international standard ITU T.88, and in 2001 as ISO/IEC 14492.
Contents
Functionality
Ideally, a JBIG2 encoder will segment the input page into regions of text, regions of halftone images, and regions of other data. Regions that are neither text nor halftones are typically compressed using a context-dependent arithmetic coding algorithm called the MQ coder. Textual regions are compressed as follows: the foreground pixels in the regions are grouped into symbols. A dictionary of symbols is then created and encoded, typically also using context-dependent arithmetic coding, and the regions are encoded by describing which symbols appear where. Typically, a symbol will correspond to a character of text, but this is not required by the compression method. For lossy compression the difference between similar symbols (e.g., slightly different impressions of the same letter) can be neglected; for lossless compression, this difference is taken into account by compressing one similar symbol using another as a template. Halftone images may be compressed by reconstructing the grayscale image used to generate the halftone and then sending this image together with a dictionary of halftone patterns. Overall, the algorithm used by JBIG2 to compress text is very similar to the JB2 compression scheme used in the DjVu file format for coding binary images.
PDF files versions 1.4 and above may contain JBIG2-compressed data. Open-source decoders for JBIG2 are jbig2dec, the java-based jbig2-imageio and the decoder found in versions 2.00 and above of xpdf. An open-source encoder is jbig2enc.
Technical details
Typically, a bi-level image consists mainly of a large amount of textual and halftone data, in which the same shapes appear repeatedly. The bi-level image is segmented into three regions: text, halftone, and generic regions. Each region is coded differently and the coding methodologies are described in the following passage.
Text image data
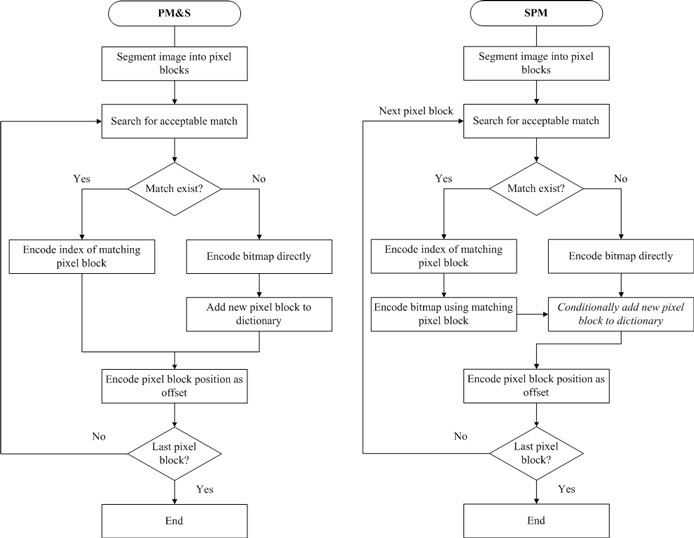
Text coding is based on the nature of human visual interpretation. A human observer cannot tell the difference between two instances of the same characters in a bi-level image even though they may not exactly match pixel by pixel. Therefore, only the bitmap of one representative character instance needs to be coded instead of coding the bitmaps of each occurrence of the same character individually. For each character instance, the coded instance of the character is then stored into a "symbol dictionary". There are two encoding methods for text image data: pattern matching and substitution (PM&S) and soft pattern matching (SPM). These methods are presented in the following subsections.
Halftones
Halftone images can be compressed using two methods. One of the methods is similar to the context-based arithmetic coding algorithm, which adaptively positions the template pixels in order to obtain correlations between the adjacent pixels. In the second method, descreening is performed on the halftone image so that the image is converted back to grayscale. The converted grayscale values are then used as indexes of fixed-sized tiny bitmap patterns contained in a halftone bitmap dictionary. This allows decoder to successfully render a halftone image by presenting indexed dictionary bitmap patterns neighboring with each other.
Arithmetic entropy coding
All three region types including text, halftone, and generic regions may all use arithmetic coding. JBIG2 specifically uses the MQ coder.
Patents
Patents for JBIG2 are owned by IBM and Mitsubishi. Free licenses should be available after a request. JBIG and JBIG2 patents are not the same.
Disadvantages
When used in lossy mode, JBIG2 compression can potentially alter text in a way that's not discernible as corruption. This is in contrast to some other algorithms, which simply degrade into a blur, making the compression artifacts obvious. Since JBIG2 tries to match up similar-looking symbols, the numbers "6" and "8" may get replaced, for example.
In 2013, various substitutions (including replacing “6” with “8”) were reported to happen on some Xerox Workcentre photocopier and printer machines, where numbers printed on scanned (but not OCRed) documents could have potentially been altered. This has been demonstrated on construction blueprints and some tables of numbers; the potential impact of such substitution errors in documents such as medical prescriptions was briefly mentioned. David Kriesel and Xerox are investigating this.
Xerox subsequently acknowledged that this was a long-standing software defect, and their initial statements in suggesting that only non-factory settings could introduce the substitution were incorrect. Patches that comprehensively address the problem were published later in August, but no attempt has been made to recall or mandate updates to the affected devices – which was acknowledged to affect more than a dozen product families. Documents previously scanned continue to potentially contain errors making their veracity difficult to substantiate. German and Swiss regulators have subsequently (in 2015) disallowed the JBIG2 encoding in archival documents.