
 | ||
Isoline retrieval is a remote sensing inverse method that retrieves one or more isolines of a trace atmospheric constituent or variable. When used to validate another contour, it is the most accurate method possible for the task. When used to retrieve a whole field, it is a general, nonlinear inverse method and a robust estimator.
Contents
Rationale
Suppose we have, as in contour advection, inferred knowledge of a single contour or isoline of an atmospheric constituent, q and we wish to validate this against satellite remote-sensing data. Since satellite instruments cannot measure the constituent directly, we need to perform some sort of inversion. In order to validate the contour, it is not necessary to know, at any given point, the exact value of the constituent. We only need to know whether it falls inside or outside, that is, is it greater than or less than the value of the contour, q0.
This is a classification problem. Let:
be the discretized variable. This will be related to the satellite measurement vector,
The accuracy of a retrieval will be given by integrating the conditional probability over the area of interest, A:
where c is the retrieved class at position,
Since this is the definition of maximum likelihood, a classification algorithm based on maximum likelihood is the most accurate method possible of validating an advected contour. A good method for performing maximum likelihood classification from a set of training data is variable kernel density estimation.
Training data
There are two methods of generating the training data. The most obvious is empirically, by simply matching measurements of the variable, q, with collocated measurements from the satellite instrument. In this case, no knowledge of the actual physics that produce the measurement is required and the retrieval algorithm is purely statistical. The second is with a forward model:
where
Error characterization
The conditional probabilities,
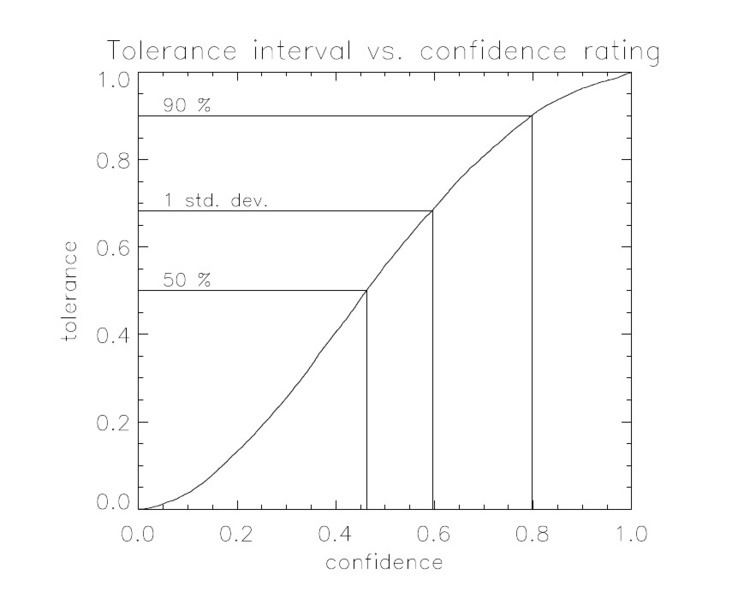
where nc is the number of classes (in this case, two). If C is zero, then the classification is little better than chance, while if it is one, then it should be perfect. To transform the confidence rating to a statistical tolerance, the following line integral can be applied to an isoline retrieval for which the true isoline is known:
where s is the path, l is the length of the isoline and
Example: water vapour from AMSU
The Advanced Microwave Sounding Unit (AMSU) series of satellite instruments are designed to detect temperature and water vapour. They have a high horizontal resolution (as little as 15 km) and because they are mounted on more than one satellite, full global coverage can be obtained in less than one day. Training data was generated using the second method from European Centre for Medium-Range Weather Forecasts (ECMWF) ERA-40 data fed to a fast radiative transfer model called RTTOV. The function,
For continuum retrievals
Isoline retrieval is also useful for retrieving a continuum variable and constitutes a general, nonlinear inverse method. It has the advantage over both a neural network, as well as iterative methods such as optimal estimation that invert the forward model directly, in that there is no possibility of getting stuck in a local minimum.
There are a number of methods of reconstituting the continuum variable from the discretized one. Once a sufficient number of contours have been retrieved, it is straightforward to interpolate between them. Conditional probabilities make a good proxy for the continuum value.
Consider the transformation from a continuum to a discrete variable:
Suppose that
where
The figure shows conditional probability versus specific humidity for the example retrieval discussed above.
As a robust estimator
The location of q0 is found by setting the conditional probabilities of the two classes to be equal:
In other words, equal amounts of the "zeroeth order moment" lie on either side of q0. This type of formulation is characteristic of a robust estimator.