
 | ||
The inode is a data structure in a Unix-style file system which describes a filesystem object such as a file or a directory. Each inode stores the attributes and disk block location(s) of the object's data. Filesystem object attributes may include metadata (times of last change, access, modification), as well as owner and permission data.
Contents
Directories are lists of names assigned to inodes. A directory contains an entry for itself, its parent, and each of its children.
Etymology
There has been uncertainty on the Linux kernel mailing list as to the reason for designating these as "i" nodes. The question was brought to Unix pioneer Dennis Ritchie, who replied:
In truth, I don't know either. It was just a term that we started to use. "Index" is my best guess, because of the slightly unusual file system structure that stored the access information of files as a flat array on the disk, with all the hierarchical directory information living aside from this. Thus the i-number is an index in this array, the i-node is the selected element of the array. (The "i-" notation was used in the 1st edition manual; its hyphen was gradually dropped.)
A paper published in 1978 by Ritchie and Ken Thompson strongly suggests the same etymology:
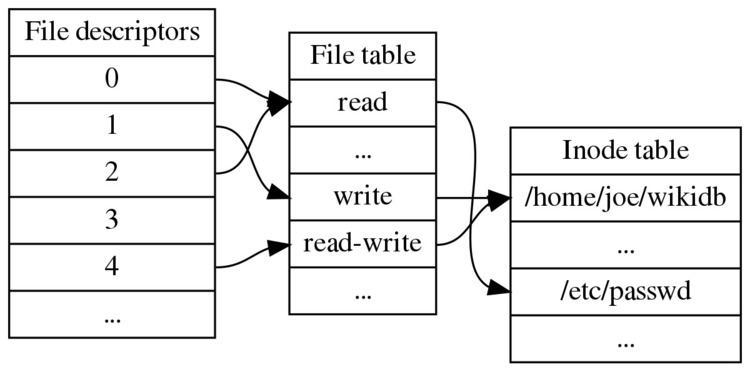
As mentioned in Section 3.2 above, a directory entry contains only a name for the associated file and a pointer to the file itself. This pointer is an integer called the i-number (for index number) of the file. When the file is accessed, its i-number is used as an index into a system table (the i-list) stored in a known part of the device on which the directory resides. The entry found thereby (the file's i-node) contains the description of the file:...
Also, Maurice J. Bach writes:
The term inode is a contraction of the term index node and is commonly used in literature on the UNIX system.
Details
A file system relies on data structures about the files, beside the file content. The former are called metadata—data that describe data. Each file is associated with an inode, which is identified by an integer number, often referred to as an i-number or inode number.
Inodes store information about files and directories (folders), such as file ownership, access mode (read, write, execute permissions), and file type. On many types of file system implementations, the maximum number of inodes is fixed at file system creation, limiting the maximum number of files the file system can hold. A typical allocation heuristic for inodes in a file system is one percent of total size.
The inode number indexes a table of inodes in a known location on the device. From the inode number, the kernel's file system driver can access the inode contents, including the location of the file - thus allowing access to the file.
A file's inode number can be found using the ls -i command. The ls -i command prints the i-node number in the first column of the report.
Some Unix-style file systems such as ReiserFS omit an inode table, but must store equivalent data in order to provide equivalent capabilities. The data may be called stat data, in reference to the stat system call that provides the data to programs.
File names and directory implications:
The operating system kernel's in-memory representation of this data is called struct inode in Linux. Systems derived from BSD use the term vnode, with the v of vnode referring to the kernel's virtual file system layer.
POSIX inode description
The POSIX standard mandates filesystem behavior that is strongly influenced by traditional UNIX filesystems. Regular files must have the following attributes:
The stat system call retrieves a file's inode number and some of the information in the inode.
Implications
Practical considerations
Many computer programs used by system administrators in Unix-like operating systems designate files with inode numbers. Examples include popular disk integrity checking utilities such as the fsck or pfiles. Thus, the need naturally arises to translate inode numbers to file pathnames and vice versa. This can be accomplished using the file finding utility find with the -inum option, or the ls command with the proper option (-i on POSIX-compliant platforms).
It is possible for a device to run out of inodes. When this happens, new files cannot be created on the device, even though there may be free space available. This is most common for use cases like mail servers which contain many small files.
Filesystems (such as JFS or XFS) escape this limitation with extents and/or dynamic inode allocation, which can 'grow' the filesystem and/or increase the number of inodes.
Inlining
It can make sense to store very small files in the inode itself to save both space (no data block needed) and look-up time (no further disk access needed). This file system feature is called inlining. The strict separation of inode and file data thus can no longer be assumed when using modern file systems.
If the data of a file fits in the space allocated for pointers to the data, this space can conveniently be used. For example, ext2 and its successors stores the data of symlinks (typically file names) in this way, if the data is no more than 60 bytes ("fast symbolic links").
Ext4 has a file system option called inline_data that, when enabled during file system creation, allows ext4 to perform inlining. As an inode's size is limited, this only works for very small files.