
 | ||
The initial attractiveness is a possible extension of the Barabási–Albert model (preferential attachment model). The Barabási–Albert model generates scale-free networks where the degree distribution can be described by a pure power law. However, the degree distribution of most real life networks cannot be described by a power law solely. The most common discrepancies regarding the degree distribution found in real networks are the high degree cut-off (or structural cut-off) and the low degree cut-off. The inclusion of initial attractiveness in the Barabási–Albert model addresses the low-degree cut-off phenomenon.
Contents
Definition
The Barabási–Albert model defines the following linear preferential attachment rule:
Based on this attachment rule it can be inferred that:
Consequences
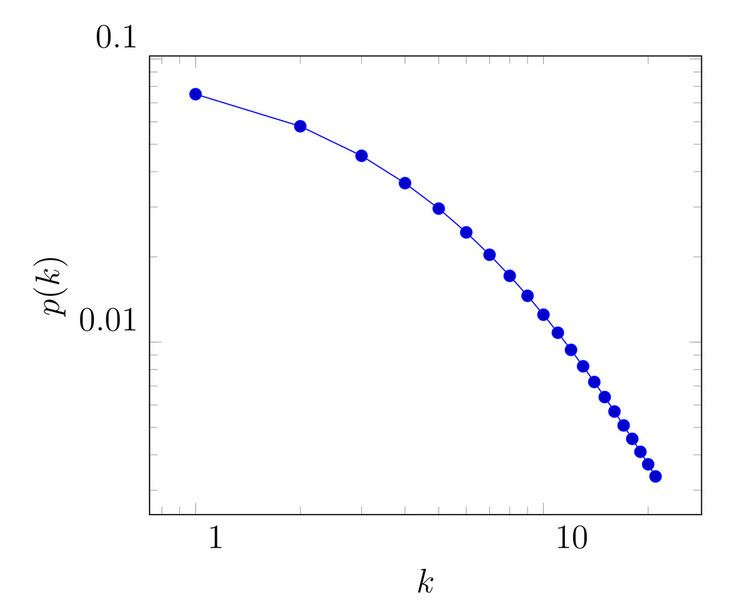
The presence of initial attractiveness results in two important consequences one is the small degree cut-off (or small degree saturation). The other on is the increased degree exponent of the degree distribution.
Small degree cut-off/saturation
The small degree saturation is an empirical regularity – the number of nodes with low degree is smaller than it would be expected if a power law would describe the degree distribution. The reason why this appears is the following: initial attractiveness increases the probability that the node obtains connection with an arriving node. This increased attachment probability becomes marginal as the node obtains more connections – it does not effect the right tail of the distribution. The degree distribution of a model with initial attractiveness can be described by the following:
Examples
There are numerous real life networks when the degree distribution shows some kind of small degree cut-off. The following list offers some examples:
Higher degree exponent
Importantly, in case of the Barabási–Albert model the exponent of the degree distribution, here denoted by