
 | ||
In statistics, an influential observation is an observation for a statistical calculation whose deletion from the dataset would noticeably change the result of the calculation. In particular, in regression analysis an influential point is one whose deletion has a large effect on the parameter estimates.
Contents
Assessment
Various methods have been proposed for measuring influence. Assume an estimated regression
-
DFBETA i ≡ b − b ( − i ) = ( X T X ) − 1 x i T e i 1 − h i b ( − i ) x i X deleted,h i = x i ( X T X ) − 1 x i T H . Thus DFBETA measures the difference in each parameter estimate with and without the influential point. There is a DFBETA for each point and each observation (if there are N points and k variables there are N·k DFBETAs). - DFFITS
- Cook's D measures the effect of removing a data point on all the parameters combined.
Outliers, leverage and influence
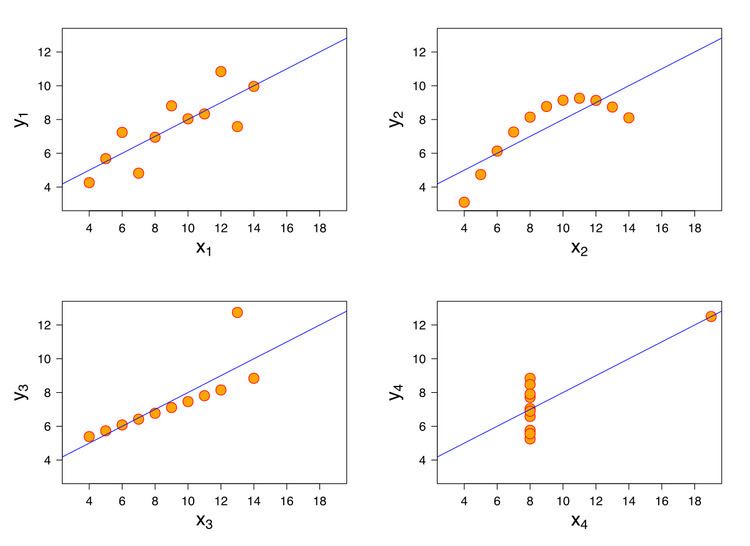
An outlier may be defined as a surprising data point. Leverage is a measure of how much the estimated value of the dependent variable changes when the point is removed. There is one value of leverage for each data point. Data points with high leverage force the regression line to be close to the point. In Anscombe's quartet, only the bottom right image has a point with high leverage.