Inductive logic programming (ILP) is a subfield of machine learning which uses logic programming as a uniform representation for examples, background knowledge and hypotheses. Given an encoding of the known background knowledge and a set of examples represented as a logical database of facts, an ILP system will derive a hypothesised logic program which entails all the positive and none of the negative examples.
Schema: positive examples + negative examples + background knowledge ⇒ hypothesis.Inductive logic programming is particularly useful in bioinformatics and natural language processing. Gordon Plotkin and Ehud Shapiro laid the initial theoretical foundation for inductive machine learning in a logical setting. Shapiro built its first implementation (Model Inference System) in 1981: a Prolog program that inductively inferred logic programs from positive and negative examples. The term Inductive Logic Programming was first introduced in a paper by Stephen Muggleton in 1991. Muggleton also founded the annual international conference on Inductive Logic Programming, introduced the theoretical ideas of Predicate Invention, Inverse resolution, and Inverse entailment,. Muggleton implemented Inverse entailment first in the PROGOL system. The term "inductive" here refers to philosophical (i.e. suggesting a theory to explain observed facts) rather than mathematical (i.e. proving a property for all members of a well-ordered set) induction.
The background knowledge is given as a logic theory B, commonly in the form of Horn clauses used in logic programming. The positive and negative examples are given as a conjunction E + and E − of unnegated and negated ground literals, respectively. A correct hypothesis h is a logic proposition satisfying the following requirements.
Necessity: B ⊭ E + Sufficiency: B ∧ h ⊨ E + Weak consistency: B ∧ h ⊭ false Strong consistency: B ∧ h ∧ E − ⊭ false "Necessity" does not impose a restriction on h, but forbids any generation of a hypothesis as long as the positive facts are explainable without it. "Sufficiency" requires any generated hypothesis h to explain all positive examples E + . "Weak consistency" forbids generation of any hypothesis h that contradicts the background knowledge B. "Strong consistency" also forbids generation of any hypothesis h that is inconsistent with the negative examples E − , given the background knowledge B; it implies "Weak consistency"; if no negative examples are given, both requirements coincide. Džeroski requires only "Sufficiency" (called "Completeness" there) and "Strong consistency".
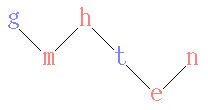
The following well-known example about learning definitions of family relations uses the abbreviations
par : parent ,
fem : female ,
dau : daughter ,
g : George ,
h : Helen ,
m : Mary ,
t : Tom ,
n : Nancy , and
e : Eve .
It starts from the background knowledge (cf. picture)
par ( h , m ) ∧ par ( h , t ) ∧ par ( g , m ) ∧ par ( t , e ) ∧ par ( n , e ) ∧ fem ( h ) ∧ fem ( m ) ∧ fem ( n ) ∧ fem ( e ) ,
the positive examples
dau ( m , h ) ∧ dau ( e , t ) ,
and the trivial proposition true to denote the absence of negative examples.
Plotkin's "relative least general generalization (rlgg)" approach to inductive logic programming shall be used to obtain a suggestion about how to formally define the daughter relation dau .
This approach uses the following steps.
Relativize each positive example literal with the complete background knowledge:Convert into clause normal form:Anti-unify each compatible pair of literals: dau ( x m e , x h t ) from dau ( m , h ) and dau ( e , t ) , ¬ par ( x h t , x m e ) from ¬ par ( h , m ) and ¬ par ( t , e ) , ¬ fem ( x m e ) from ¬ fem ( m ) and ¬ fem ( e ) , ¬ par ( g , m ) from ¬ par ( g , m ) and ¬ par ( g , m ) , similar for all other background-knowledge literals ¬ par ( x g t , x m e ) from ¬ par ( g , m ) and ¬ par ( t , e ) , and many more negated literalsDelete all negated literals containing variables that don't occur in a positive literal:after deleting all negated literals containing other variables than x m e , x h t , only dau ( x m e , x h t ) ∨ ¬ par ( x h t , x m e ) ∨ ¬ fem ( x m e ) remains, together with all ground literals from the background knowledgeConvert clauses back to Horn form: dau ( x m e , x h t ) ← par ( x h t , x m e ) ∧ fem ( x m e ) ∧ ( all background knowledge facts ) The resulting Horn clause is the hypothesis h obtained by the rlgg approach. Ignoring the background knowledge facts, the clause informally reads " x m e is called a daughter of x h t if x h t is the parent of x m e and x m e is female", which is a commonly accepted definition.
Concerning the above requirements, "Necessity" was satisfied because the predicate dau doesn't appear in the background knowledge, which hence cannot imply any property containing this predicate, such as the positive examples are. "Sufficiency" is satisfied by the computed hypothesis h, since it, together with par ( h , m ) ∧ fem ( m ) from the background knowledge, implies the first positive example dau ( m , h ) , and similarly h and par ( t , e ) ∧ fem ( e ) from the background knowledge implies the second positive example dau ( e , t ) . "Weak consistency" is satisfied by h, since h holds in the (finite) Herbrand structure described by the background knowledge; similar for "Strong consistency".
The common definition of the grandmother relation, viz. gra ( x , z ) ← fem ( x ) ∧ par ( x , y ) ∧ par ( y , z ) , cannot be learned using the above approach, since the variable y occurs in the clause body only; the corresponding literals would have been deleted in the 4th step of the approach. To overcome this flaw, that step has to be modified such that it can be parametrized with different literal post-selection heuristics. Historically, the GOLEM implementation is based on the rlgg approach.
Inductive Logic Programming system is a program that takes as an input logic theories B , E + , E − and outputs a correct hypothesis H wrt theories B , E + , E − An algorithm of an ILP system consists of two parts: hypothesis search and hypothesis selection. First a hypothesis is searched with an inductive logic programming procedure, then a subset of the found hypotheses (in most systems one hypothesis) is chosen by a selection algorithm. A selection algorithm scores each of the found hypotheses and returns the ones with the highest score. An example of score function include minimal compression length where a hypothesis with a lowest Kolmogorov complexity has the highest score and is returned. An ILP system is complete iff for any input logic theories B , E + , E − any correct hypothesis H wrt to these input theories can be found with its hypothesis search procedure.
Modern ILP systems like Progol, Hail and Imparo find a hypothesis H using the principle of the inverse entailment for theories B, E, H: B ∧ H ⊨ E ⟺ B ∧ ¬ E ⊨ ¬ H . First they construct an intermediate theory F called a bridge theory satisfying the conditions B ∧ ¬ E ⊨ F and F ⊨ ¬ H . Then as H ⊨ ¬ F , they generalize the negation of the bridge theory F with the anti-entailment. However, the operation of the anti-entailment since being highly non-deterministic is computationally more expensive. Therefore, an alternative hypothesis search can be conducted using the operation of the inverse subsumption (anti-subsumption) instead which is less non-deterministic than anti-entailment.
Questions of completeness of a hypothesis search procedure of specific ILP system arise. For example, Progol's hypothesis search procedure based on the inverse entailment inference rule is not complete by Yamamoto's example. On the other hand, Imparo is complete by both anti-entailment procedure and its extended inverse subsumption procedure.
1BC and 1BC2: first-order naive Bayesian classifiers: (http://www.cs.bris.ac.uk/Research/MachineLearning/1BC/)ACE (A Combined Engine) (http://dtai.cs.kuleuven.be/ACE/)Aleph (http://web.comlab.ox.ac.uk/oucl/research/areas/machlearn/Aleph/)Atom (http://www.ahlgren.info/research/atom/)Claudien (http://dtai.cs.kuleuven.be/claudien/)DL-Learner (http://dl-learner.org)DMax (http://dtai.cs.kuleuven.be/dmax/)FOIL (ftp://ftp.cs.su.oz.au/pub/foil6.sh)Golem (ILP) (http://www.doc.ic.ac.uk/~shm/Software/golem)ImparoInthelex (INcremental THEory Learner from EXamples) (http://lacam.di.uniba.it:8000/systems/inthelex/)Lime (http://cs.anu.edu.au/people/Eric.McCreath/lime.html)Metagol (http://github.com/metagol/metagol)Mio (http://libra.msra.cn/Publication/3392493/mio-user-s-manual)MIS (Model Inference System) by Ehud ShapiroPROGOL (http://www.doc.ic.ac.uk/~shm/Software/progol5.0)RSD (http://labe.felk.cvut.cz/~zelezny/rsd/)Tertius (http://www.cs.bris.ac.uk/publications/Papers/1000545.pdf)Warmr (now included in ACE)ProGolem (http://ilp.doc.ic.ac.uk/ProGolem/)