
 | ||
Incremental computing, also known as incremental computation, is a software feature which, whenever a piece of data changes, attempts to save time by only recomputing those outputs which depend on the changed data. When incremental computing is successful, it can be significantly faster than computing new outputs naively. For example, a spreadsheet software package might use incremental computation in its recalculation feature, to update only those cells containing formulas which depend (directly or indirectly) on the changed cells.
Contents
- Static versus Dynamic
- Specialized versus general purpose approaches
- Program derivatives
- View maintenance
- Dynamic methods
- Compiler and language support
- Frameworks and libraries
- Applications
- References
When incremental computing is implemented by a tool that can implement it for a variety of different pieces of code automatically, that tool is an example of a program analysis tool for optimization.
Static versus Dynamic
Incremental computing techniques can be broadly separated into two types of approaches:
Static approaches attempt to derive an incremental program from a conventional program P using, e.g., either manual design and refactoring, or automatic program transformations. These program transformations occur before any inputs or input changes are provided.
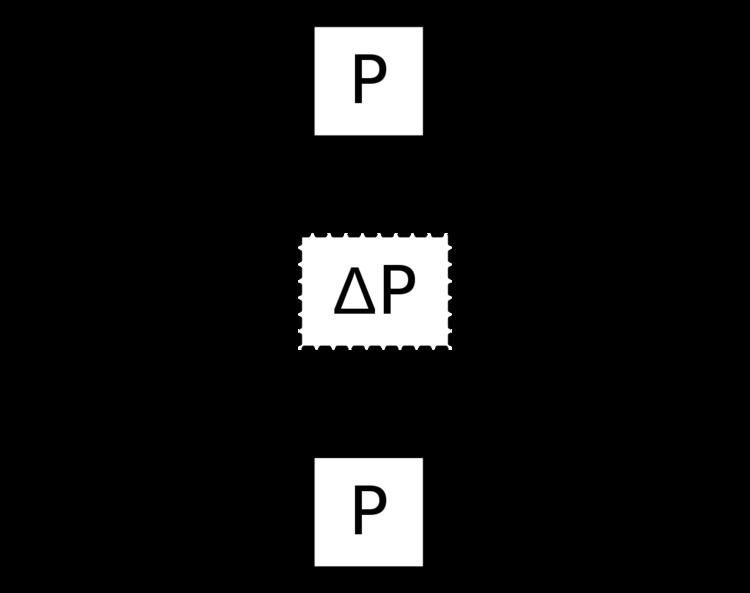
Dynamic approaches record information about executing program P on a particular input (I1) and use this information when the input changes (to I2) in order to update the output (from O1 to O2). The figure shows the relationship between program P, the change calculation function ΔP, which constitutes the core of the incremental program, and a pair of inputs and outputs, I1, O1 and I2, O2.
Specialized versus general-purpose approaches
Some approaches to incremental computing are specialized, while others are general purpose. Specialized approaches require the programmer to explicitly specify the algorithms and data structures that will be used to preserve unchanged sub-calculations. General-purpose approaches, on the other hand, use language, compiler or algorithmic techniques to give incremental behavior to otherwise non-incremental programs.
Program derivatives
Given a computation
View maintenance
In database systems such as DBToaster, views are defined with relational algebra. Incremental view maintenance statically analyzes relational algebra to create update rules that quickly maintain the view in the presence of small updates, such as insertion of a row.
Dynamic methods
A conservative (theoretically sub-optimal) implementation technique for incremental computing is for the software to build a dependency graph of all the data elements that may need to be recalculated, and their dependencies. The elements that need to be updated when a single element changes are given by the transitive closure of the dependency relation of the graph. In other words, if there is a path from the changed element to another element, the latter will be updated (even if the value does not actually change).
The dependency graph may need to be updated as dependencies change, or as elements are added to, or removed from, the system. It is used internally by the implementation, and does not typically need to be displayed to the user.
Partial evaluation can be seen as a method for automating the simplest possible case of incremental computing, in which an attempt is made to divide program data into two categories: that which can vary based on the program's input, and that which cannot (and the smallest unit of change is simply "all the data that can vary"). Of course, partial evaluation can be combined with other incremental computing techniques.
Other implementation techniques exist. For example, a topological evaluation order may be used to avoid the precomputation of elements that need to be reevaluated as in FrTime, which also avoids the problem of unnecessary updates. If a language permits cycles in the dependency graph, a single pass through the graph may not be sufficient to reach a fixed point. In many cases, complete reevaluation of a system is semantically equivalent to incremental evaluation, and may be more efficient in practice if not in theory.