
 | ||
The Gauss–Newton algorithm is used to solve non-linear least squares problems. It is a modification of Newton's method for finding a minimum of a function. Unlike Newton's method, the Gauss–Newton algorithm can only be used to minimize a sum of squared function values, but it has the advantage that second derivatives, which can be challenging to compute, are not required.
Contents
- Description
- Example
- Convergence properties
- Derivation from Newtons method
- Improved versions
- Large scale optimization
- Related algorithms
- References
Non-linear least squares problems arise for instance in non-linear regression, where parameters in a model are sought such that the model is in good agreement with available observations.
The method is named after the mathematicians Carl Friedrich Gauss and Isaac Newton.
Description
Given m functions r = (r1, …, rm) (often called residuals) of n variables β = (β1, …, βn), with m ≥ n, the Gauss–Newton algorithm iteratively finds the value of the variables which minimizes the sum of squares
Starting with an initial guess
where, if r and β are column vectors, the entries of the Jacobian matrix are
and the symbol
If m = n, the iteration simplifies to
which is a direct generalization of Newton's method in one dimension.
In data fitting, where the goal is to find the parameters β such that a given model function y = f(x, β) best fits some data points (xi, yi), the functions ri are the residuals
Then, the Gauss-Newton method can be expressed in terms of the Jacobian Jf of the function f as
Example
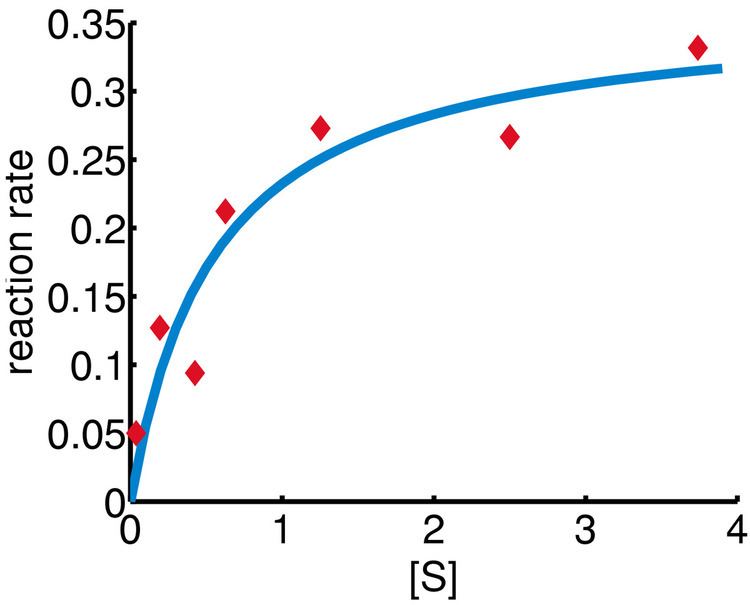
In this example, the Gauss–Newton algorithm will be used to fit a model to some data by minimizing the sum of squares of errors between the data and model's predictions.
In a biology experiment studying the relation between substrate concentration [S] and reaction rate in an enzyme-mediated reaction, the data in the following table were obtained.
It is desired to find a curve (model function) of the form
that fits best the data in the least squares sense, with the parameters
Denote by
is minimized.
The Jacobian
Starting with the initial estimates of
Convergence properties
It can be shown that the increment Δ is a descent direction for S, and, if the algorithm converges, then the limit is a stationary point of S. However, convergence is not guaranteed, not even local convergence as in Newton's method, or convergence under the usual Wolfe conditions .
The rate of convergence of the Gauss–Newton algorithm can approach quadratic. The algorithm may converge slowly or not at all if the initial guess is far from the minimum or the matrix
The optimum is at
Derivation from Newton's method
In what follows, the Gauss–Newton algorithm will be derived from Newton's method for function optimization via an approximation. As a consequence, the rate of convergence of the Gauss–Newton algorithm can be quadratic under certain regularity conditions. In general (under weaker conditions), the convergence rate is linear.
The recurrence relation for Newton's method for minimizing a function S of parameters,
where g denotes the gradient vector of S and H denotes the Hessian matrix of S. Since
Elements of the Hessian are calculated by differentiating the gradient elements,
The Gauss–Newton method is obtained by ignoring the second-order derivative terms (the second term in this expression). That is, the Hessian is approximated by
where
These expressions are substituted into the recurrence relation above to obtain the operational equations
Convergence of the Gauss–Newton method is not guaranteed in all instances. The approximation
that needs to hold to be able to ignore the second-order derivative terms may be valid in two cases, for which convergence is to be expected.
- The function values
r i - The functions are only "mildly" non linear, so that
∂ 2 r i ∂ β j ∂ β k
Improved versions
With the Gauss–Newton method the sum of squares of the residuals S may not decrease at every iteration. However, since Δ is a descent direction, unless
In other words, the increment vector is too long, but it points in "downhill", so going just a part of the way will decrease the objective function S. An optimal value for
In cases where the direction of the shift vector is such that the optimal fraction,
where D is a positive diagonal matrix. Note that when D is the identity matrix I and
The so-called Marquardt parameter,
Large-scale optimization
For large scale optimization, the Gauss-Newton method is of special interest because it is often (though certainly not always) true that the matrix
In order to make this kind of approach work, one needs at minimum an efficient method for computing the product
for some vector p. With sparse matrix storage, it is in general practical to store the rows of
so that every row contributes additively and independently to the product. In addition to respecting a practical sparse storage structure, this expression is well suited for parallel computations. Note that every row ci is the gradient of the corresponding residual ri; with this in mind, the formula above emphasizes the fact that residuals contribute to the problem independently of each other.
Related algorithms
In a quasi-Newton method, such as that due to Davidon, Fletcher and Powell or Broyden–Fletcher–Goldfarb–Shanno (BFGS method) an estimate of the full Hessian,
Another method for solving minimization problems using only first derivatives is gradient descent. However, this method does not take into account the second derivatives even approximately. Consequently, it is highly inefficient for many functions, especially if the parameters have strong interactions.