
 | ||
In computing, File Area Networking (FAN) refers to various methods of file sharing over a network, such as storage devices connected to a file server or network-attached storage (NAS).
Contents
Background
Data-storage technology over the years has evolved from a direct-attached storage model (DAS) to include two other means of connecting applications to their storage – namely Network Attached Storage (NAS) and a Storage Area Network (SAN). Since all three techniques generally differ after the file-system API level, it is possible to move between these different storage models with minimal or no impact to the applications themselves and without requiring a re-write of the application unless an application communicates directly with the storage hardware, not going through a standard interface supported by the operating system.
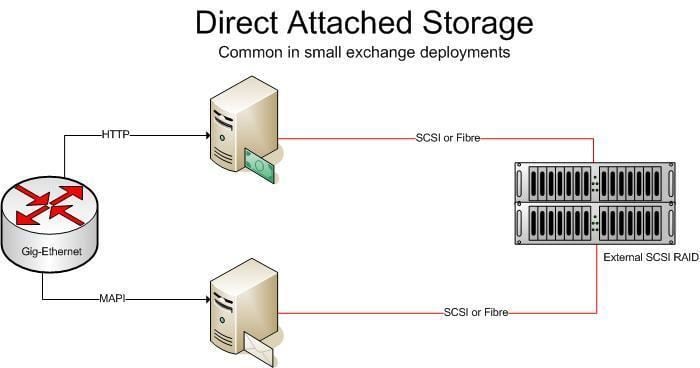
DAS
Having storage directly attached to the workstations and application servers makes management of this data intractable and an administration, compliance and maintenance nightmare. If more storage needs to be added, changes are to be made directly to the hardware where the applications are running, causing downtime. It also introduces data responsibility to the application administrators, which is not an optimal responsibility model. Furthermore, pockets (islands) of these direct attached storage cannot be used in a globally optimal manner, where storage space can be consolidated over lesser storage media. Finally, DAS introduces too much management overhead when tasks such as backups and compliance are involved.
Backup and compliance software and hardware need reach all the way into the application and workstation infrastructure to be able to perform their tasks, which typically crosses IT boundaries in enterprises as well as introduces complexity due to the lack of consolidation for these tasks.
SAN
In a SAN, the separation of the application servers and workstations from their storage medium is done at the lowest level possible in the communication stack, namely at the block IO level. Here, the raw storage commands to store and retrieve atoms of the storage (such as disk blocks) are extended from local bus access to a Fibre Channel or IP network based access (such as with iSCSI). Furthermore, SAN technologies offer a degree of virtualization such that the actual physical location and parameters of the disk are abstracted (virtualized) from the actual file system logic which runs on the application servers and workstations. However, the actual file system logic still does reside on the application servers and workstations and the file system is thus managed by them.
SAN allows storage administrators to consolidate storage and manage the data centrally, administering such tasks such as compliance, security, backup and capacity extension in one centralized location. However, the consolidation typically can extend as granular as a volume. Each volume is then managed by the storage client directly. While volumes can be virtualized, different volumes remain independent and somewhat restrict the flexibility for adds, moves and changes by the storage administrator without involving application server and workstation IT architects. The most common reason for using a SAN is where the application required direct control over the file system for reasons such as manageability and performance.
NAS
Typically NAS has been associated with storing unstructured content as files. Storage clients (such as workstations and application servers) typically use IP based network protocols such as SMB and NFS to store, retrieve and modify files on a NAS. The granularity here is the file as opposed to volumes in SANs. Many applications today use NAS, and NAS is by far the fastest growing storage model. The application servers and workstations do not control the actual file system, but rather works in a brokered model where they request file operations (such as create, read, write, delete, modify and seek) to the file servers.
NAS devices, called filers by a major vendor, are typically storage arrays with direct attached storage that communicate with application servers using file-level protocols, such as SMB or NFS. NAS heads are diskless NAS devices that translate between SMB and NFS on the front end (to the application servers) and block level storage (such as iSCSI) to the actual storage hardware. SMB and NFS are chainable protocols, which means that one NAS device can communicate SMB or NFS to the application tier and use SMB and NFS again to the actual storage network (another NAS device). As described below, such feature is a key for introducing file area networks.
Tiered Storage Model
As with solving any complex problem, breaking the storage architecture down into sub problems and viewing the storage area in tiers proves invaluable when it comes to implementation abstraction, optimization, management, changes and scaling. In mature implementations, the storage architecture is split into different categories or tiers. Each tier differs in type of hardware used, the performance of the hardware, the scale factor of that tier (amount of storage available), the availability of the tier and policies at that tier.
A very common model is to have a primary tier with expensive, high performance and limited storage. Secondary tiers typically comprise less expensive storage media and disks and can either host data migrated (or staged) by ILM software from the primary tier or can host data directly saved on the secondary tier by the application servers and workstations if those storage clients did not warrant primary tier access. Both tiers are typically serviced by a backup tier where data is copied into long term and off site storage.
HSM and ILM
Concurrently with the tiered storage model, storage architects began adopting a technique known as hierarchical storage management (or HSM) where the process would move data based on policies (such as age or importance) from one tier to the next and eventually to archive or delete the data. Since then HSM has been expanded and relabeled as Information Lifecycle Management (ILM). ILM typically is seen to have added capabilities such as logic for data classification, inspection and compliance and policy administration. Both HSM and ILM are more than a product, they are a combination of a set of procedures adopted along with software tools to carry out these policies. Many products have incorporated ILM hooks directly into the hardware with support for migration of data from one tier to the next such that such moves are as transparent as possible to the application tier.
The Storage Admission Tier (SAT)
The tiered storage architecture provides the basic framework for the application of intelligence to storage management. It provides a solid infrastructure on which data management policies can be enforced. However, the manner in which they are enforced will ultimately influence the efficiency of the storage architecture. In most storage deployments today, a tiered architecture is flat when it comes to the layer of intelligence. Each tier has limited capability to operate intelligently on the data, and the farther a tier from the actual application layer, the less information is available at that tier to operate intelligently on the files and control management of that data. A good example is HSM or ILM software which typically resides orthogonally to the tiered model as shown in the diagram below.
The ILM software for example, resides on externally induced intelligence to migrate files from one tier to the next, leaving meta data (such as shortcuts, or vendor specific stub files) on the primary as they move files to secondary tiers so as to control the storage consumed on the primary and therefore providing cost savings. While such techniques genuinely contribute toward cost savings, they have implementation overheads and have their own quirks (such as management of the stub files themselves). Furthermore, as application infrastructure changes, for example with the addition of new application services, changes are required on the ILM strategies as to the location of the data (allocated shares or volumes for that application) and policies for its migration and file management. Also, when storage operations such as backup restores are performed (for example, during disaster recovery), the HSM or ILM software will need to get involved.
Given the coupling (chaining) nature of the storage networking protocols such as SMB, NFS or iSCSI, one can see that the introduction of a tier dedicated to storage management is an architecturally correct approach to managing information stored into the storage network. Such a tier, known as the storage admission tier precedes the tier one storage services, such as those offered by a NAS filer.
Virtualize, Optimize and Manage at the SAT
The SAT introduces three core capabilities into the storage architecture:
- Primary real time storage compression
- Data de-duplication (commonality factoring), single-instance storage (SIS) and content addressed storage (CAS)
- File classification and placement techniques (HSM can be applied at this tier and the target location of the file can be decided as the file enters the network based on fingerprinting techniques, criticality of the file, or meta data such as file usage and age).
- HSM and ILM. HSM and ILM go hand in glove with file classification. This is an ongoing process and the storage admission tier is ultimately responsible for the life cycle of the data it places in the storage. SAT products continually go back and optimize data based on metadata information such as access time stamps and frequency, age of the data, departmental information and so on.
The inclusion of the SAT is primarily for the management and optimization of the data before the data even enters the primary storage tier. Sitting between the application server (or workstation) infrastructure and the primary storage, this tier has maximum visibility into application level intelligence and has most control over the management, policies, optimization and placement of the data. Having operated on the data as it enters the storage network, the storage network functionality (such as backups and restores) can be implemented independently of the optimization of the data. The VOM properties of the SAT tier aids with the implementation of well known storage techniques such as:
- Distributed and clustered file systems
- Network file management and virtualization (Global Unified Namespaces)
- Storage optimization and compression
- Storage security, access control and encryption
- Digital rights management
- File data migration, replication and placement controls (without the introduction of stub files)
- File classification and compliance
While many of the above techniques have been in play for quite sometime in varying parts of the storage architecture, they have largely been in silos and implemented without a proper model, and more importantly as overlay techniques that physically manage the data and its placement separately from the application tier that introduced the information into the storage in the first place. Not having a formal tiered approach to managing data introduces different technology components and products that compete for the management of the data and prevent the various storage techniques listed above to co-exist optimally. In such an overlay architecture approach, it is difficult to implement all storage tasks on all data globally, and instead IT departments implement subsets of these techniques.
The SAT introduces a formal model in which the above storage functions can be implemented. It ensures that these features of the storage network apply globally to the entire storage hierarchy in a uniform, centrally controlled and well planned manner.
File Area Networking (FAN)
The combination of the Storage Admission Tier (SAT), the Tiered Storage Model and NAS/SAN are known as the File Area Network (FAN). Originally coined by data storage analyst Brad O'Neill of Taneja Group, a FAN is described as a systematic approach to organizing various file-related technologies in today’s enterprises. Implementing a FAN provides IT with a scalable and flexible approach to administering intelligence to the management of file data. According to Brad O’Neill, Senior Analyst at Taneja Group, the capabilities of a FAN include:
Elements of a FAN
Based on Taneja Group’s research, below are some of the elements found in a mature FAN:
- Storage Devices - The foundation on which a FAN is built is the storage infrastructure. This can be either a SAN or a NAS environment. The only pre-requisite is that a FAN leverages a networked storage environment to enable data and resource sharing.
- File-serving devices/interfaces - Either as a directly integrated part of the storage infrastructure (e.g., NAS) or as a gateway interface (e.g., SAN), all FAN must have devices capable of serving file-level information in the form of standard protocols such as SMB and/or NFS.
- Namespaces - A FAN is based on a file system with the ability to organize, present, and store file content for authorized end clients. This capability is referred to as the file system's "namespace," a central concept in the FAN architecture. As discussed above, inherent to the SAT is the ability to abstract and virtualize the actual file system architecture from the application servers. Linking an application server or a workstation directly with a share exposed by a filer introduces management overhead when for example, maintenance tasks are performed on the filers, such as hardware upgrades. Such a tight coupling between the application tier and the data tier introduces knowledge of the underlying NAS to the application servers which should be avoided. A SAT has the ability to abstract this interface and much like a Distributed File System with referrals (DFS), SAT techniques will map network file share access requests to the actual NAS hardware, providing storage IT administrators with central control over the ultimate placement of the file data anywhere in the storage infrastructure. Such a name space is known as a Globally Unified Namespace (GUN) and provides a heterogeneous, enterprise-wide abstraction of all file level information.
- File optimization services – File data optimization techniques range anywhere from duplicate data elimination via content addressed storage and commonality factoring to complex inline compression techniques that achieve maximum storage efficiency. Controlling storage size before the file data enters the primary tier has a multiplier effect on combating costs. Enterprises will have to buy less hardware and services, and manage a lot less data. Backup and restore windows are drastically reduces and storage infrastructure upgrades become less frequent. From a storage management standpoint, simply having less data to deal with would drastically reduce expenses incurred by data expansion, and the SAT is where such storage reduction techniques can be accurately and globally made across all file content.
- File security and DRM services – Technologies to encrypt the data and administer rights management and access control must be performed centrally as data enters and leaves the primary tier. This again is a key feature of the SAT as it sits between the application and workstation access points and the primary storage tier. It also provides a central location to administer and monitor security policies, a topic which is becoming increasing important in the light of compliance and regulatory requirements in dealing with sensitive information.
- File management services – Quota administration, storage expansion and migration and replication services are a critical component of any storage infrastructure. Rather than having to deal with these services in silos on different storage islands, a SAT allows storage administrators to control these tasks at the correct tier.
- End Clients - All FANs have end client machines that access the namespaces created by file systems. The clients could be on any type of platform or computing device.
- Connectivity - There are many possible ways for a FAN to connect its end clients to the namespaces. They are commonly connected across a standard LAN using SMB or NFS, but they may simultaneously or alternatively leverage wide-area technologies, as well.