
 | ||
The Dragon Protocol is an update based cache coherence protocol used in multi-processor systems. Write propagation is performed by directly updating all the cached values across multiple processors. Update based protocols such as the Dragon protocol perform efficiently when a write to a cache block is followed by several reads made by other processors, since the updated cache block is readily available across caches associated with all the processors.
Contents
States
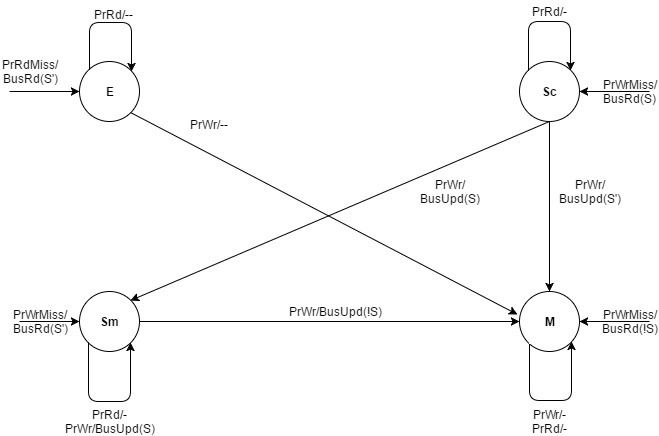
Each cache block resides in one of the four states: exclusive-clean, shared-clean, shared-modified and modify.
For any given pair of caches, the permitted states of a given cache block in conjunction with the states of the other cache's states, are as follows (the states abbreviated in the order above):
Transactions
There are 4 processor transactions and 2 bus transactions.
Processor Read (PrRd): This happens when the processor completes a successful read on a certain cache block placed in its cache.
Processor Write (PrWr): This happens when the processor completes a successful write on a certain cache block placed in its cache. This makes the processor to be the latest to update the cache block.
Processor Read Miss (PrRdMiss): This happens when the processor fails to read a cache block from its cache, and needs to fetch the block from either the memory or another cache.
Processor Write Miss (PrRdMiss): This happens when the processor fails to write to a cache block from its cache, and needs to fetch the block from the memory or another cache and then write to it. This again makes the processor to be the latest to update the cache block.
Bus Read (BusRd): This happens when a processor requests the bus to fetch the latest value of the cache block, whether it be from the main memory or another processor’s cache.
Flush: This happens when a processor places an entire cache block on the bus. This is to reflect the changes made by the processor to the cached block in the main memory.
Bus Update (BusUpd): This happens when a processor modifies a cache block, and other processors need an update in their respective cache blocks. This is unique to only write update protocols. BusUpd takes shorter time when compared to Flush operation, since writes made to caches are faster than to memory. Another point to note is that a cache cannot update its local copy of a cache block and then request the bus to send out a bus update. If this does happen, then it might be possible that two caches independently update their local copy and then request for the bus. They would then see the two writes simultaneously which would not follow Sequential consistency.
A shared line is also required to indicate whether a certain cache block is available in multiple caches. This is required because one of the caches could evict the block without needing to update the other blocks. The shared line helps reduce memory and bus transactions in some cases where the block is available in only one cache and a bus update is hence, not required. Such a dedicated line to detect sharing is seen across write-update protocols, like the Firefly protocol and implemented based on bus standards such as Futurebus (IEEE standard P896.1).
Processor-initiated transitions
Based on the current state of the block and the transaction initiated by the processor, the cache block undergoes one of the following state transitions:
Bus-initiated transitions
Based on the current state of the block and the transaction initiated by the bus, the cache block undergoes one of the following state transitions:
Elimination of the Shared-modified state
The processor with the cache block in Sm state is responsible for updating memory when the cache block is replaced. But if the main memory is updated whenever a bus update transaction occurs, there is no need for separate Sm and Sc states, and the protocol can afford a single shared state. However, this causes a lot more memory transactions which can slow down the system, especially when multiple processors are writing to the same cache block.
Broadcasting the replacement of Sc block
The protocol allows the cache blocks in the Sc state to be replaced silently without any bus activity. If a broadcast was made to let other caches know that a Sc block is being replaced, they could test the shared line and move to state E if there were no other sharers. The advantage of having a block in state E is that if the block is later written, it goes to M state and there is no need to generate a bus update transaction. So at the cost of broadcasting the replacements of Sc blocks, we are able to avoid bus update transactions. And since broadcasting replacements is not time critical, if a cache is not required to process the replacement right away, there is no downside. On the other hand, if a cache does not process an update right away, it may lead to out-of-order updates. In such cases a three state update protocol, like the Firefly protocol, may have performance advantages.
Dragon vs Write invalidate protocols
Write Invalidate is another set of cache coherence protocols, where once a cache block is modified, the other values of the same block in other caches are not updated, but invalidated. Write invalidate protocols are more efficient in cases where are there are many subsequent writes to the same cache block, as the invalidation happens once and further bus transactions by other processors are avoided. However, the write update protocol is more efficient in cases where a write to a block is followed by multiple reads to the same block. Since we are updating the other cached values once we write it, they have access to the data immediately. In such a case. the write invalidate protocol is highly disadvantageous because every time a cache block is modified in another cache, the rest of the caches need will encounter a coherence miss, and initiate a bus transaction to read the new value. In contrast, the write update protocol tends to, at times, keep the values of the block updated for longer than necessary, which will lead to an increase in other types of misses, i.e. conflict and capacity misses.
Dragon vs Firefly protocol
In case of Firefly, cache-to-cache transfers of modified blocks are also written back to main memory at the same time. But since accesses made to the main memory are slower by orders of magnitude when compared to caches, it requires added complexity of performing a write back as a separate bus operation. In any case, it results in lower performance. This problem is avoided altogether in case of Dragon protocol, since the shared blocks are not written back to memory at all. However, this comes at the cost of one added state (Shared-Dirty).