
 | ||
Domain-specific multimodeling is a software development paradigm where each view is made explicit as a separate domain-specific language (DSL).
Contents
- Motivating example
- Entity DSL
- Service DSL
- Form DSL
- Multi level customization
- Coordination problem
- Coordination as a conceptual challenge
- Coordination as a technical challenge
- Solving the coordination problem
- Coordination method
- Step 1 identification
- Step 2 specification
- Step 3 application
- Evaluation of the coordination method
- References
Successful development of a modern enterprise system requires the convergence of multiple views. Business analysts, domain experts, interaction designers, database experts, and developers with different kinds of expertise all take part in the process of building such a system. Their different work products must be managed, aligned, and integrated to produce a running system. Every participant of the development process has a particular language tailored to solve problems specific to its view on the system. The challenge of integrating these different views and avoiding the potential cacophony of multiple different languages is the coordination problem.
Domain-specific multimodeling is promising when compared to more traditional development paradigms such as single-language programming and general-purpose modeling. To reap the benefits of this new paradigm, we must solve the coordination problem. This problem is also known as the fragmentation problem in the context of Global Model Management.
One proposal to solve this problem is the coordination method. This is a three-step method to overcome the obstacles of integrating different views and coordinating multiple languages. The method prescribes how to (1) identify and (2) specify the references across language boundaries, that is the overlaps between different languages. Finally, the method offers concrete proposals on how to (3) apply this knowledge in actual development in the form of consistency, navigation, and guidance.
Motivating example
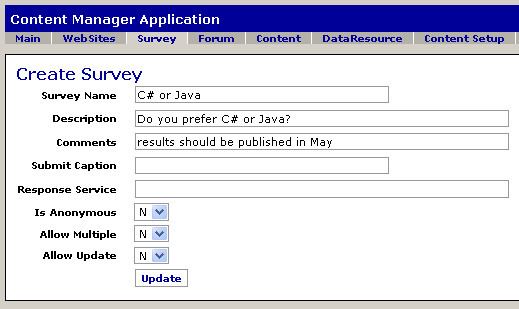
Enterprise systems based on multiple domain-specific languages are abundant. Languages with a metamodel defined in the Extensible Markup Language (XML) enjoy particularly widespread adoption. To illustrate development with multiple languages, we will draw an example from a case study: The Apache Open For Business (OFBiz) system. Briefly stated, OFBiz is an enterprise resource planning system that includes standard components such as inventory, accounting, e-commerce etc. These components are implemented by a mixture of XML-based languages and regular Java code. As an example, let us focus on the content management component, particularly a use case in which the administrative user creates an online web survey as shown in the screenshot below. We will refer to this example as the create survey example.
The figure shows a screenshot of the administrative interface of the content management application in a running OFBiz instance. To create a survey, the user fills out the fields of the input form and hits the update button. This creates a new survey which can be edited and later published on a frontend website in OFBiz. Behind the scenes, this use case involves several artifacts written in different languages. In this example, let us focus on only three of these languages: the Entity, the Service, and the Form DSL.
These three languages correspond roughly to the structural, the behavioural, and the user interface concern in OFBiz. The Entity DSL is used to describe the underlying data model and hence the way the created survey will be saved. The Service DSL is used to describe the interface of the service that is invoked when the user hits the update button. Finally, the Form DSL is used to describe the visual appearance of the form. Although the three languages are tailored for different things, they can not be separated entirely. The user interface invokes a certain application logic and this application logic manipulates the data of the application. This is an example of non-orthogonal concerns. The languages overlap because the concerns that they represent cannot be separated entirely. Let us examine these three languages in a bottom-up manner and point out their overlaps.
Entity DSL
The Entity DSL defines the structure of data in OFBiz. The listing below shows the definition of the Survey entity which is the business object that represents the concept of a survey. The code in the Listing is self-explanatory: An entity called Survey is defined with 10 fields. Each field has a name and a type. The field surveyId is used as the primary key. This definition is loaded by a central component in OFBiz called the entity engine. The entity engine instantiates a corresponding business object. The purpose of the entity engine is to manage transactional properties of all business objects and interact with various persistence mechanisms such as Java Database Connectivity, Enterprise JavaBeans or even some legacy system.
<entity entity-name="Survey" ... title="Survey Entity"> <field name="surveyId" type="id-ne"/> <field name="surveyName" type="name"/> <field name="description" type="description"/> <field name="comments" type="comment"/> <field name="submitCaption" type="short-varchar"/> <field name="responseService" type="long-varchar"/> <field name="isAnonymous" type="indicator" .../> <field name="allowMultiple" type="indicator" .../> <field name="allowUpdate" type="indicator" .../> <field name="acroFormContentId" type="id-ne" .../> <prim-key field="surveyId"/> </entity>Service DSL
The Service DSL specifies the interface of the services in OFBiz. Each service encapsulates part of the application logic of the system. The purpose of this language is to have a uniform abstraction over various implementing mechanisms. Individual services can be implemented in Java, a scripting language, or using a rule engine. The listing below shows the interface of the createSurvey service.
Apart from the name, the service element specifies the location and invocation command of the implementation for this service. The default-entity-name attribute specifies that this service refers to the Survey entity which was defined in the previous listing. This is an overlap between the two languages, specifically a so-called soft reference. A model in the Service DSL refers to a model in the Entity DSL. This reference is used in the two auto-attributes elements below which specify the input and output of the service in the form of typed attributes. As input, the service accepts attributes corresponding to all non-primary key (nonpk) fields of the Survey entity and these attributes are optional. As output, the service returns attributes corresponding to the primary key (pk) fields of Survey, i.e., in this case the surveyId field, and these attributes are mandatory. The purpose of the reference across languages is in this case to reduce redundancy. The attributes of the createSurvey service corresponds to the fields of the Survey entity and it is therefore only necessary to specify them once.
<service name="createSurvey" default-entity-name="Survey" ... location="org/ofbiz/content/survey/SurveyServices.xml" invoke="createSurvey"> ... <permission-service service-name="contentManagerPermission" main-action="CREATE"/> <auto-attributes include="nonpk" mode="IN" optional="true"/> <auto-attributes include="pk" mode="OUT" optional="false"/> </service>Form DSL
The Form DSL is used to describe the layout and visual appearance of input forms in the user interface. The language consists of domain concepts such as Form and Field. The listing below shows the implementation of the EditSurvey form. This time the Form DSL overlaps with the Service DSL. The target attribute of the form and the alt-target elements specify that the input from the submission of this form should be directed to either the updateSurvey or createSurvey services. The auto-fields-service element specifies that the form should include a field corresponding to each of the attributes of the updateSurvey service (which are similar to the attributes of the createSurvey service). This produces a similar effect of importing definitions from another model as in the case of the auto-attributes elements in the previous listing. Further down, we can see that it is possible to customize the appearance of these imported fields such as isAnonymous. Finally, a submitButton is added with a localized title such that the user can submit his data to the referenced service.
<form name="EditSurvey" type="single" target="updateSurvey" title="" default-map-name="survey"> <alt-target use-when="survey==null" target="createSurvey"/> <auto-fields-service service-name="updateSurvey"/> <field use-when="survey!=null" name="surveyId" ... /> ... <field name="isAnonymous"> <drop-down no-current-selected-key="N" allow-empty="false"> <option key="Y"/><option key="N"/> </drop-down> </field> ... <field name="submitButton" title="${uiLabelMap.CommonUpdate}" widget-style="smallSubmit"> <submit button-type="button"/> </field> </form>The create survey example, as described here, is implemented using models in three different languages. The complete implementation actually involves even more languages such as a Screen DSL to specify the layout of the screen where the form is placed, and a Minilang DSL which is a data-manipulation language used to implement the service. However, these three languages do illustrate the main idea of making each concern concrete. The example also shows a simple way of reducing redundancy by letting the languages overlap slightly.
Multi-level customization
Domain-specific languages, like those described above, have limited expressiveness. It is often necessary to add code snippets in a general-purpose language like Java to implement specialized functionality that is beyond the scope of the languages. This method is called multi-level customization. Since this method is very commonly used in setups with multiple languages, we will illustrate it by a continuation of the example. Let us call this the build PDF example.
Suppose we want to build a PDF file for each survey response to the online surveys that users create. Building a PDF file is outside the scope of our languages so we need to write some Java code that can invoke a third-party PDF library to perform this specialized functionality. Two artifacts are required:
First, an additional service model, as shown below, in the Service DSL that defines the interface of the concrete service such that it can be accessed on the modeling level. The service model describes the location of the implementation and what the input and output attributes are.
<service name="buildPdfFromSurveyResponse" engine="java" location="org.ofbiz.content.survey.PdfSurveyServices" invoke="buildPdfFromSurveyResponse"> <attribute name="surveyResponseId" mode="IN" optional="false" .../> <attribute name="outByteWrapper" mode="OUT" optional="false" .../> </service>Second, we need a code snippet, as shown below, that contains the actual implementation of this service. A service can have multiple inputs and outputs so input to the Java method is a map, called context, from argument names to argument values and returns output in the form of another map, called results.
public static Map buildPdfFromSurveyResponse (DispatchContext dctx , Map context) { String id = (String) context.get("surveyResponseId"); Map results = new HashMap(); try { ...the response is retrieved from the database... ...a pdf is built from the response... ...the pdf is serialized as a bytearray... ByteWrapper outByteWrapper = ...; results.put("outByteWrapper",outByteWrapper ); } catch (Exception e) {} return results; }This multi-level customization method uses soft references similar to the create survey example. The main difference is that the reference here is between model and code rather than between model and model. The advantage, in this case, is that a third-party Java library for building PDFs can be leveraged. Another typical application is to use Java code snippets to invoke external webservices and import results in a suitable format.
Coordination problem
The example illustrates some of the advantages of using multiple languages in development. There are, however, also difficulties associated with this kind of development. These difficulties stem from the observation that the more kinds of artifacts we introduce into our process, the more coordination between developer efforts is needed. We will refer to these difficulties as the Coordination Problem. The Coordination Problem has a conceptual and a technical aspect. Conceptually, the main problem is to understand the different languages and their interaction. To properly design and coordinate models in multiple languages, developers must have a sufficient understanding of how languages interact. Technically, the main problem is to enforce consistency. Tools must be provided to detect inconsistencies early, i.e., at modeling time, and assist developers in resolving these inconsistencies. In the following, we will examine these two aspects in greater detail.
Coordination as a conceptual challenge
The first problem that developers encounter when starting on development with multiple languages is language cacophony. Learning the different languages and understanding their interaction is necessary to make sense of the complex composition of artifacts. The OFBiz framework for instance has seventeen different languages and more than 200 000 lines of domain-specific language code so the complexity can be quite overwhelming! There is currently no established method of characterizing different languages such that developers quickly can reach an operational understanding. Tools are important here as an ad hoc mechanism for learning and exploration because developers typically use tools to learn by experiments. There are especially three areas where tools for domain-specific models are helpful:
- Understanding a language
- Understanding language interactions
- Understanding how to use languages
First, understanding a language can be difficult and in the case of XML-based domain-specific languages a frequent and intuitive objection is the syntax matters objection. This argument can be stated in the following way: “The different languages are hard to understand and only add to the confusion because their XML-based syntax is particularly verbose and unintelligible. Using a single general-purpose language like Java would be better because then developers could rely on a syntax that they already know”. While this objection is certainly important, it misses a central point. XML or a similar representation format may not be the syntax that developers actually work with. One of the advantages of using XML-based domain-specific languages is that we can then provide domain-specific editors. The figure below shows what a hypothetical editor for the Entity DSL might look like. This editor presents the domain in a simple and visually appealing manner but may very well use the XML representation (and perhaps a layout configuration) underneath.
Just as we may complain that XML is a bad choice, we could also object that a general-purpose language like Java is a poor choice for some tasks. Furthermore, developers may feel less intimidated by the editor in figure than by code Listings in XML or Java. If we accept that syntax matters then the use of different languages with tailored editors becomes a reasonable strategy. The simplicity of the editor makes the language easier to understand and hence easier to use. In other words, the syntax matters objection may be the very reason why we explore the field of Domain-specific languages.
Second, language interactions reveal relations between languages. Developers should be able to jump between related elements in different artifacts. Ease of navigation between different software artifacts is an important criterion for tools in traditional development environments. Although we have performed no empirical studies in this area, we hypothesize that proper navigation facilities increase productivity. This claim is supported by the observation that all major development environments today offer quite sophisticated navigation facilities such as type hierarchy browser or the ability to quickly locate and jump to references to a method definition. The development environments can provide these navigation facilities because they maintain a continuously updated model of the sourcefiles in the form of an abstract syntax tree.
In a development environment with multiple languages, navigation is much more difficult. Existing environments are not geared to parsing and representing DSL models as abstract syntax trees for arbitrary and perhaps even application-specific languages such as the languages from the previous example. Furthermore without this internal representation, existing environments cannot resolve neither intra- nor inter-language references for such languages and hence cannot provide useful navigation. This means that developers must maintain a conceptual model of how the parts of their system are related. New tools with navigation facilities geared to multiple languages would on the other hand be very helpful in understanding the relations between languages. In terms of the create survey example such tools should display the relations between the three languages by using the soft references as navigation points.
Third, to understand language use we must be able to distinguish correct editing operations from wrong ones in our development environment. Traditional development environments have long provided guidance during the writing of a program. Incremental compilation allows the environment to offer detailed suggestions to the developer such as how to complete a statement. More intrusive kinds of guidance also exist such as syntax-oriented editors where only input conforming to the grammar can be entered. Generic text-editors that can be parameterized with the grammar of a language have existed for a long time.
Existing editors do not take inter-language consistency relations into account when providing guidance. In the previous example, an ideal editor should for instance be able to suggest the createSurvey service as a valid value when the developer edits the target attribute in the Form definition. An environment which could reason about artifacts from different languages would also be able to help the developer identify program states where there was local but not global consistency. Such a situation can arise when a model is well-formed and hence locally consistent but at the same time violates an inter-language constraint. Guidance or intelligent assistance in the form of proposals on how to complete a model would be useful for setups with multiple languages and complex consistency constraints. Tool-suggested editing operations could make it easier for the developer to get started on the process of learning how to use the languages.
Coordination as a technical challenge
The technical aspect of the coordination problem is essentially a matter of enforcing consistency. How can we detect inconsistencies across models from multiple languages at modeling time? To fully understand the complexity of the consistency requirements of a system based on multiple languages, it is useful to refine our concept of consistency.
Consistency can be either intra- or inter-consistency. Intra-consistency concerns the consistency of elements within a single model. The requirements here are that the model must conform to its metamodel, i.e., be syntactically well-formed. In terms of the create survey example, the entity model must for instance conform to the XSD schema of the Entity DSL. This schema is the metamodel of the Entity DSL and it specifies how elements can be composed and what are, to some extent, the valid domains of attributes.
Inter-consistency is achieved when references across language boundaries can be resolved. This kind of consistency can be further subdivided into (1) model-to-model consistency and (2) model-to-code consistency. Model-to-model consistency concerns the referential integrity as well as high-level constraints of the system. In the create survey example, the default-entity-name attribute from the Service listing refers to the name attribute from Entity listing. If we change one of these values without updating the other, we break the reference. More high-level consistency constraints across different models also exist as discussed later. A project can have certain patterns or conventions for naming and relating model elements. Current development environments must be tailored to specific languages with handwritten plugins or similar mechanisms in order to enforce consistency between languages such as those from the previous example.
Model-to-code consistency is an essential requirement in multi-level customization. When models are supplemented with code snippets as in the build PDF example, it is necessary to check that models and code actually fit. This partly a matter of making sure that soft references between models and code are not broken, similar to referential integrity in model-to-model consistency. But it is also a matter of making sure that the code does not violate expectations set up in the model. In the build PDF example, the model specifies that outByteWrapper will always be part of the output, i.e., the outByteWrapper key is put in the results map. An analysis of the code shows that outByteWrapper will only be part of the output if no exceptions are thrown before line 10. In other words, some possible executions of the code will violate a specification on the modeling level. More generally, we can state that multi-level customization imposes very fine-grained constraints on the involved models and code snippets.
Solving the coordination problem
The coordination problem arises from the fact that multiple languages are used in a single system. The two previous Subsections illustrate that this problem has both a conceptual side as well as a low-level technical side. The challenges that we have described are real rather than hypothetical challenges. Specifically, we have faced these challenges in two concrete and representative case studies: an enterprise resource planning system, OFBiz, and a health care system, the District Health Information System (DHIS). Both cases are medium-sized systems that are in actual industrial use. Our solution to the practical problems we have encountered during our work with these systems are a set of guidelines and prototypes. In the following, we will introduce an overall conceptual framework which incorporates the guidelines and prototypes into a coherent method: the coordination method.
Coordination method
The goal of the coordination method is to solve the coordination problem and thereby provide better support for development with multiple languages. To properly appreciate the method, it is important to understand that it does not prescribe the design of individual languages. Plenty of methods and tools have already been proposed for this. This method assumes the existence of a setup with multiple domain-specific languages. Given such a setup, one can apply the method. The method consists of three steps as shown in the diagram below. Each step consist of a couple of parts which are shown as little boxes in the diagram. Boxes with dotted lines represent automatic processes and boxes with solid lines represent manual ones. In the following, we will explain these steps in a bit more detail.
Step 1: identification
The goal of the identification step is to identify language overlaps. As described in the example, an overlap is an area where the concerns of two languages intersect. The soft references from Form DSL to Service DSL and from Service DSL to Entity DSL in the create survey use case are examples of such overlaps. Another example is the case where a customized code snippet is used to extend a model. Such overlaps are frequent when the expressiveness of general-purpose languages is needed to implement specialized requirements that are beyond the scope of the model. The identification step can either be a manual or an automatic process depending on the complexity of the overlaps. When the overlaps have been identified and made explicit, this information is used as input to the second step in the method: the specification step.
Step 2: specification
The goal of the specification step is to create a coordination model which specifies how languages interact. The references across language boundaries in a system constitute the coordination model for that particular system. It is created by mapping the main software artifacts into a common representation. Additional information such as domain- or application-specific constraints may also be encoded to provide a rich representation. The coordination model is based on generic information such as language grammars and constraints as well as application-specific information such as concrete models and application-specific constraints. This means that even though the same languages are used across several products, each product has a specification of its own unique coordination model. The coordination model is used as basis for various forms of reasoning in the final step of the method: the application step.
Step 3: application
The goal of the application step is to take advantage of the coordination model. The coordination model allows tools to derive three layers of useful information. First, the coordination model can be used to enforce consistency across multiple languages. The coordination model specifies consistency relations such as how elements from different languages can refer to each other. Tools can enforce referential integrity and perform static checks of the final system before deployment. Second, the consistency relations are used to navigate, visualize and map the web of different languages in a development setup. This information is used to quickly link and relate elements from different languages and to provide traceability among different models. Third, based on consistency relations and navigational information about how elements are related, tools can provide guidance, specifically completion or assistance. Model completion can for instance be provided in a generic manner across domain-specific tools.
Evaluation of the coordination method
The coordination method can best be seen as a conceptual framework that prescribes a certain workflow when working with multiple languages. The three successive steps that constitute this workflow are not supported by an integrated workbench or development environment. The focus is rather on extending the developer's existing environments to add support for (1) identification, (2) specification, and (3) application. The main advantage of this approach has been that developers have actually tested our work and given us feedback. This kind of evaluation of the method is valuable because it reduces the risk of solving a purely hypothetical problem. Several papers introduce the different steps of the coordination method, report on this evaluation, and elaborates on the technical aspects of each individual experiment. Overall, the results have been promising: a significant number of errors have been found in production systems and given rise to a constructive dialog with developers on future tool requirements. A development process based on these guidelines and supported by tools constitutes a serious attempt to solve the coordination problem and make domain-specific multimodeling a practical proposition.