
 | ||
In computer science, distributed shared memory (DSM) is a form of memory architecture where physically separated memories can be addressed as one logically shared address space. Here, the term "shared" does not mean that there is a single centralized memory, but that the address space is "shared" (same physical address on two processors refers to the same location in memory). Distributed global address space (DGAS), is a similar term for a wide class of software and hardware implementations, in which each node of a cluster has access to shared memory in addition to each node's non-shared private memory.
Contents
- Methods of Achieving DSM
- Software DSM Implementation
- Message Passing vs DSM
- Advantages of DSM
- Disadvantages of DSM
- Directory Memory Coherence
- States
- Home centric Request and Response
- Advantages
- Disadvantages
- Requester centric Request and Response
- Consistency Models
- Replication in DSM
- Release and Entry Consistency
- Examples
- References
A distributed-memory system, often called a multicomputer, consists of multiple independent processing nodes with local memory modules which is connected by a general interconnection network. Software DSM systems can be implemented in an operating system, or as a programming library and can be thought of as extensions of the underlying virtual memory architecture. When implemented in the operating system, such systems are transparent to the developer; which means that the underlying distributed memory is completely hidden from the users. In contrast, software DSM systems implemented at the library or language level are not transparent and developers usually have to program them differently. However, these systems offer a more portable approach to DSM system implementations. A distributed shared memory system implements the shared-memory model on a physically distributed memory system.
Methods of Achieving DSM
There are usually two methods of achieving distributed shared memory:
Software DSM Implementation
There are three ways of implementing a software distributed shared memory:
Message Passing vs. DSM
Software DSM systems also have the flexibility to organize the shared memory region in different ways. The page based approach organizes shared memory into pages of fixed size. In contrast, the object based approach organizes the shared memory region as an abstract space for storing shareable objects of variable sizes. Another commonly seen implementation uses a tuple space, in which the unit of sharing is a tuple.
Shared memory architecture may involve separating memory into shared parts distributed amongst nodes and main memory; or distributing all memory between nodes. A coherence protocol, chosen in accordance with a consistency model, maintains memory coherence.
Advantages of DSM
Disadvantages of DSM
Directory Memory Coherence
Memory coherence is necessary such that the system which organizes the DSM is able to track and maintain the state of data blocks in nodes across the memories comprising the system.
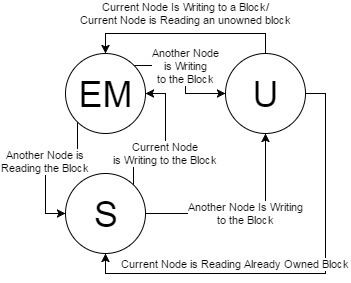
States
A basic DSM will track at least three states among nodes for any given block in the directory. There will be some state to dictate the block as uncached (U), a state to dictate a block as exclusively owned or modified owned (EM), and a state to dictate a block as shared (S). As blocks come into the directory organization, they will transition from U to EM (ownership state) in the initial node, then state can transition to S when other nodes begin reading the block.
There are a two primary methods for allowing the system to track where blocks are cached and in what condition across each node. Home-centric request-response uses the home to service requests and drive states, whereas requester-centric allows each node to drive and manage its own requests through the home.
Home-centric Request and Response
In a home-centric system, the DSM will avoid having to handle request-response races between nodes by allowing only one transaction to occur at a time until the home node has decided that the transaction is finished - usually when home has received all responding processor's response to the request. An example of this is Intel's QPI home-source mode.
Advantages
Disadvantages
Requester-centric Request and Response
In a requester-centric system, the DSM will allow nodes to talk at will to each other through the home. This means that multiple nodes can attempt to start a transaction, but this requires additional considerations to ensure coherence. For example: when one node is processing a block, if it receives a request for that block from another node it will send a NAck (Negative Acknowledgement) to tell the initiator that the processing node can't fulfill that request right away. An example of this is Intel's QPI snoop-source mode.
Advantages
Disadvantages
Consistency Models
The DSM must follow certain rules to maintain consistency over how read and write order is viewed among nodes, called the system's consistency model.
Suppose we have n processes and Mi memory operations for each process i, and that all the operations are executed sequentially. We can conclude that (M1 + M2 + … + Mn)!/(M1! M2!… Mn!) are possible interleaves of the operations. The issue with this conclusion is determining the correctness of the interleaved operations. Memory coherence for DSM defines which interleaves are permitted.
Replication in DSM
Replication of shared data in general tends to:
However, preserving coherence and consistency may become more challenging.