
 | ||
DSSim' is an ontology mapping system, that has been conceived to achieve a certain level of the envisioned machine intelligence on the Semantic Web. The main driving factors behind its development was to provide an alternative to the existing heuristics or machine learning based approaches with a multi-agent approach that makes use of uncertain reasoning. The system provides a possible approach to establish machine understanding over Semantic Web data through multi-agent beliefs and conflict resolution.
Contents
Theoretical background
The DSSim framework for ontology mapping was introduced in 2005 by Miklos Nagy and Maria Vargas-Vera at the Open University (OU). DSSim addresses three challenges of the Semantic Web:
DSSim uses novel 3D visualisation techniques of both mapping and reasoning results. The main purpose of the reasoning storage and visualisation is to retain the reasoning states, in order to visualise it later to the end users. The main objective is to show to the end users why the system has selected a mapping candidate from two different ontologies.
Evaluation of the system
The evaluation of the system was carried out in the Ontology Alignment Evaluation Initiative (OAEI). DSSim has participated in 2006, 2007, 2008 and 2009 achieving gradually improved results. The following sections present the result of two tracks out of 8 from the OAEI 2008.
Library track at OAEI 2008
According to the original task definition provided by the organizers of the OAEI 2008, the library track involved the alignment of two Dutch thesauri. These Dutch thesauri are used to index books from two collections held by the National Library of the Netherlands (KB). KB maintains two big collections: the Deposit Collection, containing all the Dutch printed publications (one million items), and the Scientific Collection, with about 1.4 million books mainly about the history, language and culture of the Netherlands. Each collection is described according to its own indexing system and conceptual vocabulary. On the one hand, the Scientific Collection was described using the GTT, a huge vocabulary containing 35,000 general concepts ranging from Wolkenkrabbers (Sky-scrapers) to Verzorging (Care). On the other hand, the books contained in the Deposit Collection are mainly indexed against the Brinkman thesaurus, containing a large set of headings (more than 5,000) that were expected to serve as global subjects of books. For each concept, the thesauri provided the usual lexical and semantic information: preferred labels, synonyms and notes, broader and related concepts, etc. The language of both thesauri was Dutch, but a quite substantial part of Brinkman concepts (around 60%) come with English labels. The library track was difficult partly because of its relative large size and because of its multilingual representation. Nevertheless in the library track DSSim has performed the best out of the 3 participating systems. However these ontologies contain related and broader terms therefore the mapping can be carried out without consulting multi-lingual background knowledge.
Directory track at OAEI 2008
As stated by the original task definition provided by the organizers of the OAEI 2008, this track is designed to evaluate mapping quality in a real world taxonomy integration scenario. The main objective is to measure whether ontology alignment tools can effectively be applied to integration of "shallow ontologies". The evaluation dataset was extracted from Google, Yahoo and Looksmart web directories. The way these ontology pairs were created was to rely on a reference interpretation for nodes, constructed by looking at their use. The assumption was that the semantics of nodes could have been derived from their pragmatics, namely from analysing, which documents were classified under which nodes. The basic idea was therefore to compute the relationship hypotheses based on the co-occurrence of documents. The specific characteristics of the dataset were:
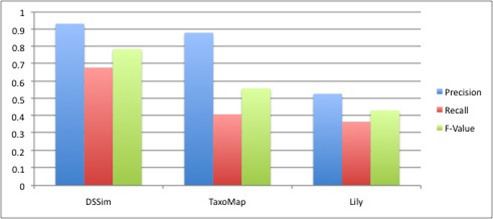
In the directory track only 6 systems have participated in 2008. In terms of F-value DSSim has performed the best however the difference was marginal compared to the CIDER or Lily systems.