
 | ||
DOPIPE parallelism is a method to perform loop-level parallelism by pipelining the statements in a loop. Pipelined parallelism may exist at different levels of abstraction like loops, functions and algorithmic stages. The extent of parallelism depends upon the programmers' ability to make best use of this concept. It also depends upon factors like identifying and separating the independent tasks and executing them parallelly.
Contents
Background
The main purpose of employing loop-level parallelism is to search and split sequential tasks of a program and convert them into parallel tasks without any prior information about the algorithm. Parts of data that are recurring and consume significant amount of execution time are good candidates for loop-level parallelism. Some common applications of loop-level parallelism are found in mathematical analysis that uses multiple-dimension matrices which are iterated in nested loops.
There are different kind of parallelization techniques which are used on the basis of data storage overhead, degree of parallelization and data dependencies. Some of the known techniques are: DOALL, DOACROSS and DOPIPE.
DOALL: This technique is used where we can parallelize each iteration of the loop without any interaction between the iterations. Hence, the overall run-time gets reduced from N * T (for a serial processor, where T is the execution time for each iteration) to only T (since all the N iterations are executed in parallel).
DOACROSS: This technique is used wherever there is a possibility for data dependencies. Hence, we parallelize tasks in such a manner that all the data independent tasks are executed in parallel, but the dependent ones are executed sequentially. There is a degree of synchronization used to sync the dependent tasks across parallel processors.
Description
DOPIPE is a pipelined parallelization technique that is used in programs where each element produced during each iteration is consumed in the later iteration. The following example shows how to implement the DOPIPE technique to reduce the total execution time by breaking the tasks inside the loop and executing them in a pipelined manner. The breaking into tasks takes place in such a way that all the dependencies within the loop are unidirectional, i.e. the following iteration does not depend on the previous iteration.
Example
The program below shows a pseudocode for DOPIPE parallelization.
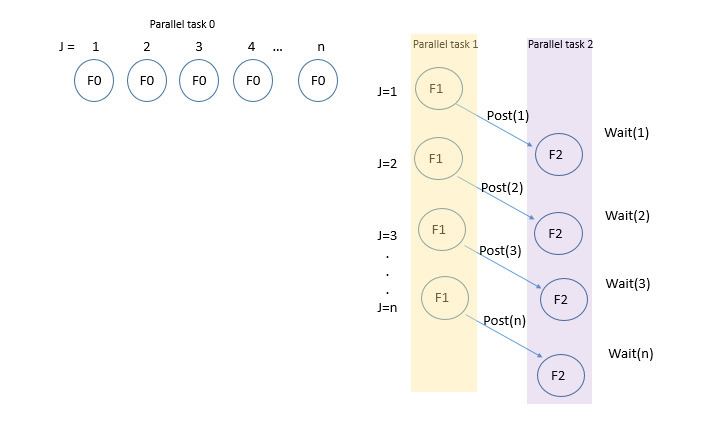
In this code, we see that there are three tasks (F0, F1 and F2) inside a loop iterating over j for 1 to N. Following is a list of dependencies in the code:
F1[j] → T F1[j+1], implies that statement F1 in iteration j+1 must be executed after statement F1 in iteration j. This is also known as true dependency.
F1[j] → T F2[j], implies that statement F2 in iteration j must be executed after statement F1 in iteration j.
If this code would have been executed sequentially, then the total time consumed would be equal to N * (TF0 + TF1 + TF2), where TF0, TF1 and TF2 denote execution time for functions F0, F1 and F2 respectively per iteration. Now, if we parallelize the loop by pipelining the statements inside the loop in the following manner:
for (j=1; j<=N; j++) { F0: o[j] = x[j] - a[j]; //DOALL parallelism}for (j=1; j<=N; j++) { F1: z[j] = z[j-1] * 5; //DOPIPE parallelism post(j); //The result of F1 is posted and available for use}for (j=1; j<=N; j++) { wait(j); //It waits till the F1 completes and produces the value z[j] to be used by F2 F2: y[j] = z[j] * w[j];}Since, F0 is an independent function, i.e. it does not have any loop-carried dependency (no dependence on j+1 or j-1 iterations). Neither it has any dependency across other statements in the loop. Hence, we can completely separate out this function and run it parallelly using DOALL parallelism. On the other hand, Statements F1 and F2 are dependent (explained above), therefore we split them into two different loops and execute them in a pipelined fashion. We use post(j) and wait(j) to synchronize between F1 and F2 loops.
Starting from the first iteration of j, statement F1 gets executed in TF1 time. Meanwhile, F2 is not getting executed since it is waiting for the value z[j] to be produced by F1. When F1 completes its execution for iteration j, it posts the value using post(j). After waiting for F1's execution, using wait(j), F2 starts its execution since it has the value z[j] available for use. Also, since F1's execution is not restricted by F2, hence F1 executes j+1 simultaneously. The figure below shows the execution timeline of all the statements.
From the figure, we see that the total time to execute F0 is TF0, since all the iterations of F0 are executed in parallel. While for F1 and F2, the total execution time is equal to N * TF1 + TF2 (considering negligible synchronization time).
This is considerably less than the time obtained during sequential execution.
Comparison with other models
DOALL parallelism mainly works on principle of divide and conquer. Here all the tasks run in different iterations that use unique set of data. So the problem with this implementation is that when large amount of data works is computed together, a large cache space is needed to work for different threads. Since there is no dependencies in the threads, there is no overhead for the inter - thread communication.
While in DOPIPE, there is a synchronization overhead between the threads. But, due to its pipelined structure, it requires less cache space because the data produced is immediately consumed by the consumer.