
 | ||
In statistics, a confounding variable (also confounding factor, a confound, a lurking variable or a confounder) is a variable in a statistical model that correlates (directly or inversely) with both the dependent variable and an independent variable, in a way that "explains away" some or all of the correlation between these two variables.
Contents
While specific definitions may vary, in essence a confounding variable fits the following four criteria, here given in a hypothetical situation with variable of interest "V", confounding variable "C" and outcome of interest "O":
- C is associated (inversely or directly) with O
- C is associated with O, independent of V
- C is associated (inversely or directly) with V
- C is not in the causal pathway of V to O (C is not a direct consequence of V, not a way by which V produces O)
The preceding correlation-based definition, however, is metaphorical at best – a growing number of analysts agree that confounding is a causal concept, and as such, cannot be described in terms of correlations nor associations (see causal definition).
Causal definition
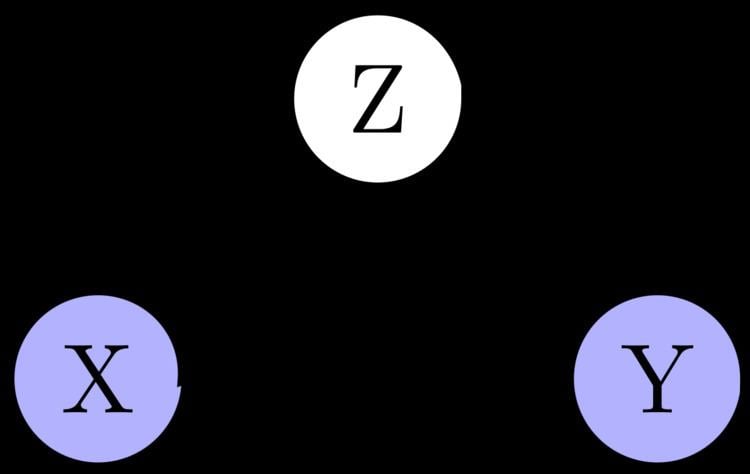
The concept of confounding must be defined, and managed, in terms of the data generating model (as in the Figure above). Specifically, let X be some independent variable, Y some dependent variable. To estimate the effect of X on Y, the statistician must suppress the effects of extraneous variables that influence both X and Y. We say that, X and Y are confounded by some other variable Z whenever Z is a cause of both X and Y.
In the causal framework, denote
for all values X = x and Y = y, where
In principle, the defining equality P(y|(x)) = P(y|x) can be verified from the data generating model assuming we have all the equations and probabilities associated with the model. This is done by simulating an intervention do(X = x) (see Bayesian Networks) and checking whether the resulting probability of Y equals the conditional probability P(y|x). It turns out, however, that graph structure alone is sufficient for verifying the equality P(y|x)= P(y|x).
Control
Consider a researcher attempting to assess the effectiveness of drug X, from population data in which drug usage was a patient's choice. Data show that gender(Z) differences influence a patient's choice of drug as well as their chances of recovery (Y). In this scenario, gender Z confounds the relation between X and Y since Z is a cause of both X and Y:
Indeed, we will encounter the inequality:
because the observational quantity contains information about the correlation between X and Z, and the interventional quantity does not (since X is not correlated with Z in a randomized experiment). Clearly the statistician desires the unbiased estimate
which gives an unbiased estimate for the causal effect of X on Y. The same adjustment formula works when there are multiple confounders except, in this case, the choice of a set Z of variables that would guarantee unbiased estimates must be done with caution. The criterion for a proper choice of variables is called the Back-Door and requires that the chosen set Z "blocks" (or intercepts) every path from X to Y that ends with an arrow into X. Such sets are called "Back-Door admissible" and may include variables which are not common causes of X and Y, but merely proxies thereof.
Returning to the drug use example, since Z complies with the Back-Door requirement (i.e., it intercepts the one Back-Door path X
In this way the physician can predict the likely effect of administering the drug from observational studies in which the conditional probabilities appearing on the right-hand side of the equation can be estimated by regression.
Contrary to common beliefs, adding covariates to the adjustment set Z can introduce bias. A typical counterexample occurs when Z is a common effect of X and Y, a case in which Z is not a confounder (i.e., the null set is Back-door admissible) and adjusting for Z would create bias known as "collider bias" or "Berkson's paradox."
In general, confounding can be controlled by adjustment if and only if there is a set of observed covariates that satisfies the Back-Door condition. Moreover, if Z is such a set, then the adjustment formula of Eq. (3) is valid <4,5>. Pearl's do-calculus provide additional conditions under which P(y|do(x)) can be estimated, not necessarily by adjustment.
History
According to Morabia (2011), the word derives from the Medieval Latin verb "confudere", which meant "mixing", and was probably chosen to represent the confusion between the cause one wishes to assess and other causes that may affect the outcome and thus confuse, or stand in the way of the desired assessment. Fisher used the word "confounding" in his 1935 book "The Design of Experiments" to denote any source of error in his ideal of randomized experiment. According to Vandenbroucke (2004) it was Kish who used the word "confounding" in the modern sense of the word, to mean "incomparability" of two or more groups (e.g., exposed and unexposed) in an observational study.
Formal conditions defining what makes certain groups "comparable" and others "incomparable" were later developed in epidemiology by Greenland and Robins (1986) using the counterfactual language of Neyman (1935) and Rubin (1974). These were later supplemented by graphical criteria such as the Back-Door condition (Pearl 1993; Greenland, Pearl and Robins, 1999).
Graphical criteria were shown to be formally equivalent to the counterfactual definition, but more transparent to researchers relying on process models.
Types
In the case of risk assessments evaluating the magnitude and nature of risk to human health, it is important to control for confounding to isolate the effect of a particular hazard such as a food additive, pesticide, or new drug. For prospective studies, it is difficult to recruit and screen for volunteers with the same background (age, diet, education, geography, etc.), and in historical studies, there can be similar variability. Due to the inability to control for variability of volunteers and human studies, confounding is a particular challenge. For these reasons, experiments offer a way to avoid most forms of confounding.
In some disciplines, confounding is categorized into different types. In epidemiology, one type is "confounding by indication", which relates to confounding from observational studies. Because prognostic factors may influence treatment decisions (and bias estimates of treatment effects), controlling for known prognostic factors may reduce this problem, but it is always possible that a forgotten or unknown factor was not included or that factors interact complexly. Confounding by indication has been described as the most important limitation of observational studies. Randomized trials are not affected by confounding by indication due to random assignment.
Confounding variables may also be categorised according to their source. The choice of measurement instrument (operational confound), situational characteristics (procedural confound), or inter-individual differences (person confound).
Examples
As an example, suppose that there is a statistical relationship between ice-cream consumption and number of drowning deaths for a given period. These two variables have a positive correlation with each other. An evaluator might attempt to explain this correlation by inferring a causal relationship between the two variables (either that ice-cream causes drowning, or that drowning causes ice-cream consumption). However, a more likely explanation is that the relationship between ice-cream consumption and drowning is spurious and that a third, confounding, variable (the season) influences both variables: during the summer, warmer temperatures lead to increased ice-cream consumption as well as more people swimming and thus more drowning deaths.
In another concrete example, say one is studying the relation between birth order (1st child, 2nd child, etc.) and the presence of Down's Syndrome in the child. In this scenario, maternal age would be a confounding variable:
- Higher maternal age is directly associated with Down's Syndrome in the child
- Higher maternal age is directly associated with Down's Syndrome, regardless of birth order (a mother having her 1st vs 3rd child at age 50 confers the same risk)
- Maternal age is directly associated with birth order (the 2nd child, except in the case of twins, is born when the mother is older than she was for the birth of the 1st child)
- Maternal age is not a consequence of birth order (having a 2nd child does not change the mother's age)
In risk assessments, factors such as age, gender, and educational levels often affect health status and so should be controlled. Beyond these factors, researchers may not consider or have access to data on other causal factors. An example is on the study of smoking tobacco on human health. Smoking, drinking alcohol, and diet are lifestyle activities that are related. A risk assessment that looks at the effects of smoking but does not control for alcohol consumption or diet may overestimate the risk of smoking. Smoking and confounding are reviewed in occupational risk assessments such as the safety of coal mining. When there is not a large sample population of non-smokers or non-drinkers in a particular occupation, the risk assessment may be biased towards finding a negative effect on health.
Decreasing the potential for confounding
A reduction in the potential for the occurrence and effect of confounding factors can be obtained by increasing the types and numbers of comparisons performed in an analysis. If measures or manipulations of core constructs are confounded (i.e. operational or procedural confounds exist), subgroup analysis may not reveal problems in the analysis. Additionally, increasing the number of comparisons can create other problems (see multiple comparisons).
Peer review is a process that can assist in reducing instances of confounding, either before study implementation or after analysis has occurred. Peer review relies on collective expertise within a discipline to identify potential weaknesses in study design and analysis, including ways in which results may depend on confounding. Similarly, replication can test for the robustness of findings from one study under alternative study conditions or alternative analyses (e.g., controlling for potential confounds not identified in the initial study).
Confounding effects may be less likely to occur and act similarly at multiple times and locations. In selecting study sites, the environment can be characterized in detail at the study sites to ensure sites are ecologically similar and therefore less likely to have confounding variables. Lastly, the relationship between the environmental variables that possibly confound the analysis and the measured parameters can be studied. The information pertaining to environmental variables can then be used in site-specific models to identify residual variance that may be due to real effects.
Depending on the type of study design in place, there are various ways to modify that design to actively exclude or control confounding variables:
All these methods have their drawbacks:
- The best available defense against the possibility of spurious results due to confounding is often to dispense with efforts at stratification and instead conduct a randomized study of a sufficiently large sample taken as a whole, such that all potential confounding variables (known and unknown) will be distributed by chance across all study groups and hence will be uncorrelated with the binary variable for inclusion/exclusion in any group.
- Ethical considerations: In double blind and randomized controlled trials, participants are not aware that they are recipients of sham treatments and may be denied effective treatments. There is resistance to randomized controlled trials in surgery because patients would agree to invasive surgery which carry risks under the understanding that they were receiving treatment.