
 | ||
The Classification Tree Method is a method for test design, as it is used in different areas of software development. It was developed by Grimm and Grochtmann in 1993. Classification Trees in terms of the Classification Tree Method must not be confused with decision trees.
Contents
- Application
- Example
- Background
- Classification Tree Method for Embedded Systems
- Dependency Rules and Automated Test Case Generation
- Prioritized Test Case Generation
- Test Sequence Generation
- Numerical Constraints
- Classification Tree Editor
- CTE 1
- CTE 2
- CTE XL
- CTE XL Professional
- TESTONA
- Advantages
- Limitations
- References
The classification tree method consists of two major steps:
- Identification of test relevant aspects (so called classifications) and their corresponding values (called classes) as well as
- Combination of different classes from all classifications into test cases.
The identification of test relevant aspects usually follows the (functional) specification (e.g. requirements, use cases …) of the system under test. These aspects form the input and output data space of the test object.
The second step of test design then follows the principles of combinatorial test design.
While the method can be applied using a pen and a paper, the usual way involves the usage of the Classification Tree Editor, a software tool implementing the classification tree method.
Application
Prerequisites for applying the classification tree method (CTM) is the selection (or definition) of a system under test. The CTM is a black-box testing method and supports any type of system under test. This includes (but is not limited to) hardware systems, integrated hardware-software systems, plain software systems, including embedded software, user interfaces, operating systems, parsers, and others (or subsystems of mentioned systems).
With a selected system under test, the first step of the classification tree method is the identification of test relevant aspects. Any system under test can be described by a set of classifications, holding both input and output parameters. (Input parameters can also include environments states, pre-conditions and other, rather uncommon parameters). Each classification can have any number of disjoint classes, describing the occurrence of the parameter. The selection of classes typically follows the principle of equivalence partitioning for abstract test cases and boundary-value analysis for concrete test cases. Together, all classifications form the classification tree. For semantic purpose, classifications can be grouped into compositions.
The maximum number of test cases is the Cartesian product of all classes of all classifications in the tree, quickly resulting in large numbers for realistic test problems. The minimum number of test cases is the number of classes in the classification with the most containing classes.
In the second step, test cases are composed by selecting exactly one class from every classification of the classification tree. The selection of test cases originally was a manual task to be performed by the test engineer.
Example
For a database system, test design has to be performed. Applying the classification tree method, the identification of test relevant aspects gives the classifications: User Privilege, Operation and Access Method. For the User Privileges, two classes can be identified: Regular User and Administrator User. There are three Operations: Add, Edit and Delete. For the Access Method, again three classes are identified: Native Tool, Web Browser, API. The Web Browser class is further refined with the test aspect Brand, three possible classes are included here: Internet Explorer, Mozilla Firefox, and Apple Safari.
The first step of the classification tree method now is complete. Of course, there are further possible test aspects to include, e.g. access speed of the connection, number of database records present in the database, etc. Using the graphical representation in terms of a tree, the selected aspects and their corresponding values can quickly be reviewed.
For the statistics, there are 30 possible test cases in total (2 privileges * 3 operations * 5 access methods). For minimum coverage, 5 test cases are sufficient, as there are 5 access methods (and access method is the classification with the highest number of disjoint classes).
In the second step, three test cases have been manually selected:
- A regular user adds a new data set to the database using the native tool.
- An administrator user edits an existing data set using the Firefox browser.
- A regular user deletes a data set from the database using the API.
Background
The CTM introduced the following advantages over the Category Partition Method (CPM) by Olstrad and Balcer:
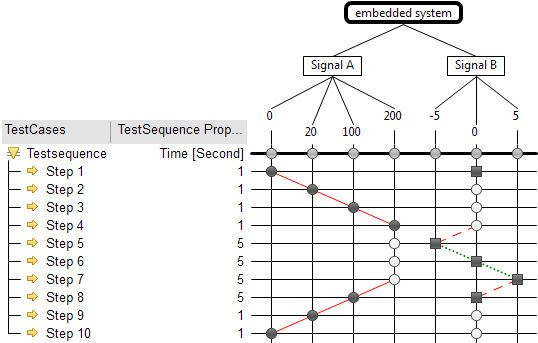
Classification Tree Method for Embedded Systems
The classification tree method first was intended for the design and specification of abstract test cases. With the classification tree method for embedded systems, test implementation can also be performed. Several additional features are integrated with the method:
- In addition to atomic test cases, test sequences containing several test steps can be specified.
- A concrete timing (e.g. in Seconds, Minutes ...) can be specified for each test step.
- Signal transitions (e.g. linear, spline, sine ...) between selected classes of different test steps can be specified.
- A distinction between event and state can be modelled, represented by different visual marks in a test.
The module and unit testing tool Tessy relies on this extension.
Dependency Rules and Automated Test Case Generation
One way of modelling constraints is using the refinement mechanism in the classification tree method. This, however, does not allow for modelling constraints between classes of different classifications. Lehmann and Wegener introduced Dependency Rules based on Boolean expressions with their incarnation of the CTE. Further features include the automated generation of test suites using combinatorial test design (e.g. all-pairs testing).
Prioritized Test Case Generation
Recent enhancements to the classification tree method include the prioritized test case generation: It is possible to assign weights to the elements of the classification tree in terms of occurrence and error probability or risk. These weights are then used during test case generation to prioritize test cases. Statistical testing is also available (e.g. for wear and fatigue tests) by interpreting the element weights as a discrete probability distribution.
Test Sequence Generation
With the addition of valid transitions between individual classes of a classification, classifications can be interpreted as a state machine, and therefore the whole classification tree as a Statechart. This defines an allowed order of class usages in test steps and allows to automatically create test sequences. Different coverage levels are available, such as state coverage, transitions coverage and coverage of state pairs and transition pairs.
Numerical Constraints
In addition to Boolean dependency rules referring to classes of the classification tree, Numerical Constraints allow to specify formulas with classifications as variables, which will evaluate to the selected class in a test case.
Classification Tree Editor
The Classification Tree Editor (CTE) is a software tool for test design that implements the classification tree method.
Over the time, several editions of the CTE tool have appeared, written in several (by that time popular) programming languages and developed by several companies.
CTE 1
The original version of CTE was developed at Daimler-Benz Industrial Research facilities in Berlin. It appeared in 1993 and was written in Pascal. It was only available on Unix systems.
CTE 2
In 1997 a major re-implementation was performed, leading to CTE 2. Development again was at Daimler-Benz Industrial Research. It was written in C and available for win32 systems.
CTE 2 was later licensed to Razorcat for inclusion with the module and unit testing tool Tessy. The classification tree editor for embedded systems also based upon this edition.
CTE XL
In 2000, Lehmann and Wegener introduced Dependency Rules with their incarnation of the CTE, the CTE XL (eXtended Logics). Further features include the automated generation of test suites using combinatorial test design (e.g. all-pairs testing).
Development was performed by DaimlerChrysler. CTE XL was written in Java and was supported on win32 systems. CTE XL was available for download free of charge.
In 2008, Berner&Mattner acquired all rights on CTE XL and continued development till CTE XL 1.9.4.
CTE XL Professional
Starting in 2010, CTE XL Professional was developed by Berner&Mattner. A complete re-implementation was done, again using Java but this time Eclipse-based. CTE XL Professional was available on win32 and win64 systems.
New developments included:
TESTONA
In 2014, Berner&Mattner started releasing its classification tree editor under the brand name TESTONA.
A free edition of TESTONA is still available for download free of charge, however, with reduced functionality.