
 | ||
Cache prefetching is a technique used by computer processors to boost execution performance by fetching instructions or data from their original storage in slower memory to a faster local memory before it is actually needed (hence the term 'prefetch'). Most modern computer processors have fast and local cache memory in which prefetched data is held till it is required. The source for the prefetch operation is usually main memory. Because of their design, accessing cache memories is typically much faster than accessing main memory, so prefetching data and then accessing it from caches is usually many orders of magnitude faster than accessing it directly from main memory.
Contents
Metrics of cache prefetching
There are three main metrics to judge cache prefetching
Coverage
Coverage is the fraction of total misses that are eliminated because of prefetching, i.e
where,
Accuracy
Accuracy is the fraction of total prefetches that were useful - i.e. the ratio of the number of memory addresses prefetched were actually referenced by the program to the total prefetches done.
While it appears that having perfect accuracy might imply that there are no misses, this is not the case. The prefetches themselves might result in new misses if the prefetched blocks are placed directly into the cache. Although these are a very small fraction of the total number of misses we might see without any prefetching, this is still a small non-zero finite number of misses.
Timeliness
The qualitative definition of timeliness is how early a block is prefetched versus when it is actually referenced. An example to further explain timeliness is as follows :
Consider a for loop where each iteration takes 12 cycles to execute and the 'prefetch' operation takes 3 cycles. This implies that for the prefetched data to be useful, we must start the prefetch
Types of cache prefetching
There are two main types of cache prefetching,
Hardware based prefetching is typically accomplished by having a dedicated hardware mechanism in the processor that watches the stream of instructions or data being requested by the executing program, recognizes the next few elements that the program might need based on this stream and prefetches into the processor's cache.
Software based prefetching is typically accomplished by having the compiler analyze the code and insert additional "prefetch" instructions in the program during compilation itself.
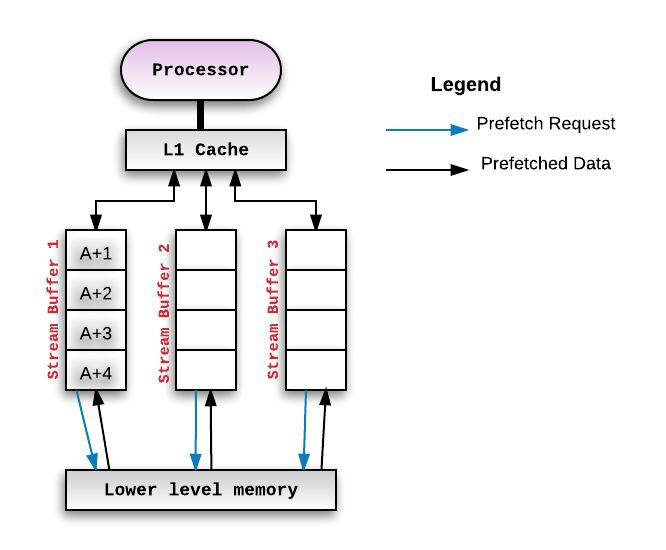
Stream buffers
Another pattern of prefetching instructions is to prefetch addresses that are
Compiler directed prefetching
Compiler directed prefetching is widely used within loops with a large number of iterations. In this technique, the compiler predicts future cache misses and inserts a prefetch instruction based on the miss penalty and execution time of the instructions.
These prefetches are non-blocking memory operations, i.e these memory accesses do not interfere with actual memory accesses. They do not change the state of the processor or cause page faults.
One main advantage of software prefetching is that it reduces the number of compulsory cache misses.
The following example shows the how a prefetch instruction will be added into a code to improve cache performance.
Consider a for loop as shown below:
At each iteration, the ith element of the array "array1" is accessed. Therefore, we can prefetch the elements that are going to be accessed in future iterations by inserting a "prefetch" instruction as shown below:
Here, the prefetch stride,