
 | ||
A CAPTCHA (a backronym for "Completely Automated Public Turing test to tell Computers and Humans Apart") is a type of challenge-response test used in computing to determine whether or not the user is human.
Contents
- Origin and inventorship
- Relation to AI
- Circumvention
- Machine learning based attacks
- Cheap or unwitting human labor
- Insecure implementation
- Notable attacks
- Alternative CAPTCHAs schemas
- References
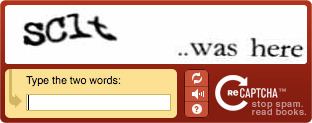
The term was coined in 2003 by Luis von Ahn, Manuel Blum, Nicholas J. Hopper, and John Langford. The most common type of CAPTCHA was first invented in 1997 by two groups working in parallel: (1) Mark D. Lillibridge, Martin Abadi, Krishna Bharat, and Andrei Z. Broder; and (2) Reshef, Raanan and Solan. This form of CAPTCHA requires that the user type the letters of a distorted image, sometimes with the addition of an obscured sequence of letters or digits that appears on the screen. Because the test is administered by a computer, in contrast to the standard Turing test that is administered by a human, a CAPTCHA is sometimes described as a reverse Turing test.
This user identification procedure has received many criticisms, especially from disabled people, but also from other people who feel that their everyday work is slowed down by distorted words that are difficult to read. It takes the average person approximately 10 seconds to solve a typical CAPTCHA.
Origin and inventorship
Since the early days of the Internet, users have wanted to make text illegible to computers. The first such people could be hackers, posting about sensitive topics to online forums they thought were being automatically monitored for keywords. To circumvent such filters, they would replace a word with look-alike characters. HELLO could become |-|3|_|_() or )-(3££0, as well as numerous other variants, such that a filter could not possibly detect all of them. This later became known as leetspeak.
Subsequent to that work, two teams of people have claimed to be the first to invent the CAPTCHAs used throughout the Web today. The first team consists of Mark D. Lillibridge, Martín Abadi, Krishna Bharat, and Andrei Broder, who used CAPTCHAs in 1997 at AltaVista to prevent bots from adding URLs to their web search engine. Looking for a way to make their images resistant to OCR attack, the team looked at the manual of their Brother scanner, which had recommendations for improving OCR's results (similar typefaces, plain backgrounds, etc.). The team created puzzles by attempting to simulate what the manual claimed would cause bad OCR.
The second team to claim inventorship of CAPTCHAs consists of Luis von Ahn, Manuel Blum, Nicholas J. Hopper, and John Langford, who first described CAPTCHAs in a 2003 publication and subsequently received much coverage in the popular press. Their notion of CAPTCHA covers any program that can distinguish humans from computers, including many different examples of CAPTCHAs.
The controversy of inventorship has been resolved by the existence of a 1997 priority date patent application by Reshef, Raanan and Solan who worked at Sanctum on Application Security Firewall. Their patent application details that "The invention is based on applying human advantage in applying sensory and cognitive skills to solving simple problems that prove to be extremely hard for computer software. Such skills include, but are not limited to processing of sensory information such as identification of objects and letters within a noisy graphical environment"; and a 1998 patent by Lillibridge, Abadi, Bharat, and Broder,. Both patents predate other publications by several years, though they do not use the term CAPTCHA, they describe the ideas in detail and precisely depict the graphical CAPTCHAs used in the Web today.
Relation to AI
While used mostly for security reasons, CAPTCHAs also serve as a benchmark task for artificial intelligence technologies. According to an article by Ahn, Blum and Langford, “Any program that passes the tests generated by a CAPTCHA can be used to solve a hard unsolved AI problem.”
They argue that the advantages of using hard AI problems as a means for security are twofold. Either the problem goes unsolved and there remains a reliable method for distinguishing humans from computers, or the problem is solved and a difficult AI problem is resolved along with it. In the case of image and text based CAPTCHAs, if an AI were capable of accurately completing the task without exploiting flaws in a particular CAPTCHA design, then it would have solved the problem of developing an AI that is capable of complex object recognition in scenes.
CAPTCHAs based on reading text — or other visual-perception tasks — prevent blind or visually impaired users from accessing the protected resource. However, CAPTCHAs do not have to be visual. Any hard artificial intelligence problem, such as speech recognition, can be used as the basis of a CAPTCHA. Some implementations of CAPTCHAs permit users to opt for an audio CAPTCHA despite the fact that Audio CAPTCHAs have been demonstrated insecure.
For non-sighted users (for example blind users, or color blind people on a color-using test), visual CAPTCHAs present serious problems. Because CAPTCHAs are designed to be unreadable by machines, common assistive technology tools such as screen readers cannot interpret them. Since sites may use CAPTCHAs as part of the initial registration process, or even every login, this challenge can completely block access. In certain jurisdictions, site owners could become targets of litigation if they are using CAPTCHAs that discriminate against certain people with disabilities. For example, a CAPTCHA may make a site incompatible with Section 508 in the United States. In other cases, those with sight difficulties can choose to identify a word being read to them.
While providing an audio CAPTCHA allows blind users to read the text, it still hinders those who are both blind and deaf. According to sense.org.uk, about 4% of people over 60 in the UK have both vision and hearing impairments. There are about 23,000 people in the UK who have serious vision and hearing impairments. According to The National Technical Assistance Consortium for Children and Young Adults Who Are Deaf-Blind (NTAC), the number of deafblind children in the USA increased from 9,516 to 10,471 during the period 2004 to 2012. Gallaudet University quotes 1980 to 2007 estimates which suggest upwards of 35,000 fully deafblind adults in the USA. Deafblind population estimates depend heavily on the degree of impairment used in the definition.
The use of CAPTCHA thus excludes a small number of individuals from using significant subsets of such common Web-based services as PayPal, GMail, Orkut, Yahoo!, many forum and weblog systems, etc.
Even for perfectly sighted individuals, new generations of graphical CAPTCHAs, designed to overcome sophisticated recognition software, can be very hard or impossible to read.
A method of improving the CAPTCHA to ease the work with it was proposed by ProtectWebForm and was called "Smart CAPTCHA". Developers advise to combine the CAPTCHA with JavaScript support. Since it is too hard for most of spam robots to parse and execute JavaScript, using a simple script which fills the CAPTCHA fields and hides the image and the field from human eyes was proposed.
One alternative method involves displaying to the user a simple mathematical equation and requiring the user to enter the solution as verification. Although these are much easier to defeat using software, they are suitable for scenarios where graphical imagery is not appropriate, and they provide a much higher level of accessibility for blind users than the image-based CAPTCHAs. These are sometimes referred to as MAPTCHAs (M = 'mathematical'). However, these may be difficult for users with a cognitive disorder.
Other kinds of challenges, such as those that require understanding the meaning of some text (e.g., a logic puzzle, trivia question, or instructions on how to create a password) can also be used as a CAPTCHA. Again, there is little research into their resistance against countermeasures.
Circumvention
There are a few approaches to defeating CAPTCHAs: using cheap human labor to recognize them, exploiting bugs in the implementation that allow the attacker to completely bypass the CAPTCHA, and finally using machine learning to build an automated solver. According to former Google click fraud czar Shuman Ghosemajumder, there are numerous criminal services which solve CAPTCHAs automatically.
Machine learning-based attacks
In its earliest iterations there was not a systematic methodology for designing or evaluating CAPTCHAs. As a result, there were many instances in which CAPTCHAs were of a fixed length and therefore automated tasks could be constructed to successfully make educated guesses about where segmentation should take place. Other early CAPTCHAs contained limited sets of words, which made the test much easier to game. Still others made the mistake of relying too heavily on background confusion in the image. In each case, algorithms were created that were successfully able to complete the task by exploiting these design flaws. These methods proved brittle however, and slight changes to the CAPTCHA were easily able to thwart them. Modern CAPTCHAs like reCAPTCHA no longer rely just on fixed patterns but instead present variations of characters that are often collapsed together, making segmentation almost impossible. These newest iterations have been much more successful at warding off automated tasks.
In October 2013, artificial intelligence company Vicarious claimed that it had developed a generic CAPTCHA-solving algorithm that was able to solve modern CAPTCHAs with character recognition rates of up to 90%. However, Luis von Ahn, a pioneer of early CAPTCHA and founder of reCAPTCHA, expressed skepticism, stating: "It's hard for me to be impressed since I see these every few months." He pointed out that 50 similar claims to that of Vicarious had been made since 2003.
In August 2014 at Usenix WoOT conference Bursztein et al. presented the first generic CAPTCHA-solving algorithm based on reinforcement learning and demonstrated its efficiency against many popular CAPTCHA schemas. They concluded that text distortion based CAPTCHAs schemes should be considered insecure moving forward.
Cheap or unwitting human labor
It may be possible to subvert CAPTCHAs by relaying them to a sweatshop of human operators who are employed to decode CAPTCHAs. A 2005 paper from a W3C working group stated that such an operator "could easily verify hundreds of them each hour". In 2010 the university of UCSD conducted a large scale study of those CAPTCHA's farms and found out that the retail price for solving one million CAPTCHAs is as low as $1,000.
Another technique used consists of using a script to re-post the target site's CAPTCHA as a CAPTCHA to a site owned by the attacker, which unsuspecting humans visit and correctly solve within a short while for the script to use. However, there is controversy around the economic viability of such attack.
Insecure implementation
Howard Yeend has identified two implementation issues with poorly designed CAPTCHA systems:
Sometimes, if part of the software generating the CAPTCHA is client-side (the validation is done on a server but the text that the user is required to identify is rendered on the client side), then users can modify the client to display the un-rendered text. Some CAPTCHA systems use MD5 hashes stored client-side, which may leave the CAPTCHA vulnerable to a brute-force attack.
Notable attacks
Some notable attacks against various CAPTCHAs schemas include:
Alternative CAPTCHAs schemas
With the demonstration that text distortion based CAPTCHAs are vulnerable to machine learning based attacks, some researchers have proposed alternatives including image recognition CAPTCHAs which require users to identify simple objects in the images presented. The argument in favor of these schemes is that tasks like object recognition are typically more complex to perform than text recognition and therefore should be more resilient to machine learning based attacks. Here are some of notable alternative CAPTCHA schemas: