
 | ||
The Box–Muller transform, by George Edward Pelham Box and Mervin Edgar Muller 1958, is a pseudo-random number sampling method for generating pairs of independent, standard, normally distributed (zero expectation, unit variance) random numbers, given a source of uniformly distributed random numbers.
Contents
It is commonly expressed in two forms. The basic form as given by Box and Muller takes two samples from the uniform distribution on the interval [0, 1] and maps them to two standard, normally distributed samples. The polar form takes two samples from a different interval, [−1, +1], and maps them to two normally distributed samples without the use of sine or cosine functions.
The Box–Muller transform was developed as a more computationally efficient alternative to the inverse transform sampling method. The Ziggurat algorithm gives an even more efficient method. Furthermore, the Box–Muller transform can be employed for drawing from truncated bivariate Gaussian densities.
Basic form
Suppose U1 and U2 are independent random variables that are uniformly distributed in the interval (0, 1). Let
and
Then Z0 and Z1 are independent random variables with a standard normal distribution.
The derivation is based on a property of a two-dimensional Cartesian system, where X and Y coordinates are described by two independent and normally distributed random variables, the random variables for R2 and Θ (shown above) in the corresponding polar coordinates are also independent and can be expressed as
and
Because R2 is the square of the norm of the standard bivariate normal variable (X, Y), it has the chi-squared distribution with two degrees of freedom. In the special case of two degrees of freedom, the chi-squared distribution coincides with the exponential distribution, and the equation for R2 above is a simple way of generating the required exponential variate.
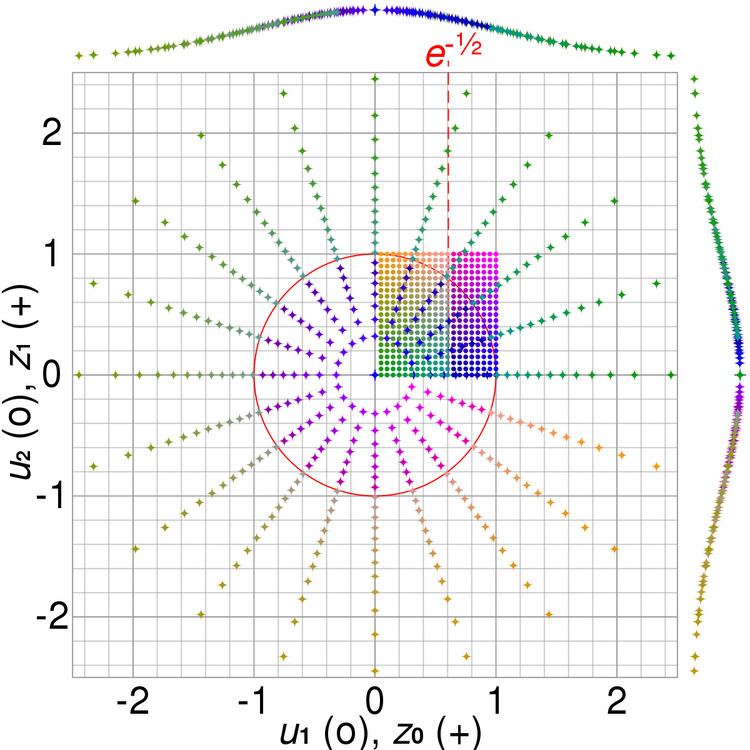
Polar form
The polar form was first proposed by J. Bell and then modified by R. Knop. While several different versions of the polar method have been described, the version of R. Knop will be described here because it is the most widely used, in part due to its inclusion in Numerical Recipes.
Given u and v, independent and uniformly distributed in the closed interval [−1, +1], set s = R2 = u2 + v2. (Clearly
We now identify the value of s with that of U1 and
Just as the basic form produces two standard normal deviates, so does this alternate calculation.
and
Contrasting the two forms
The polar method differs from the basic method in that it is a type of rejection sampling. It discards some generated random numbers, but it is typically faster than the basic method because it is simpler to compute (provided that the random number generator is relatively fast) and is more numerically robust. It avoids the use of trigonometric functions, which are comparatively expensive in many computing environments. It discards 1 − π/4 ≈ 21.46% of the total input uniformly distributed random number pairs generated, i.e. discards 4/π − 1 ≈ 27.32% uniformly distributed random number pairs per Gaussian random number pair generated, requiring 4/π ≈ 1.2732 input random numbers per output random number.
The basic form requires two multiplications, 1/2 logarithm, 1/2 square root, and one trigonometric function for each normal variate. On some processors, the cosine and sine of the same argument can be calculated in parallel using a single instruction. Notably for Intel-based machines, one can use the fsincos assembler instruction or the expi instruction (usually available from C as an intrinsic function), to calculate complex
and just separate the real and imaginary parts.
The polar form requires 3/2 multiplications, 1/2 logarithm, 1/2 square root, and 1/2 division for each normal variate. The effect is to replace one multiplication and one trigonometric function with a single division.
Tails truncation
When a computer is used to produce a uniform random variable it will inevitably have some inaccuracies because there is a lower bound on how close numbers can be to 0. If the generator uses 32 bits per output value, the smallest non-zero number that can be generated is
Implementation
The standard Box–Muller transform generates values from the standard normal distribution (i.e. standard normal deviates) with mean 0 and standard deviation 1. The implementation below in standard C++ generates values from any normal distribution with mean rand has not been seeded, the same series of values will always be returned from the generateGaussianNoise function.