
 | ||
In coding theory, a block code is any member of the large and important family of error-correcting codes that encode data in blocks. There is a vast number of examples for block codes, many of which have a wide range of practical applications. Block codes are conceptually useful because they allow coding theorists, mathematicians, and computer scientists to study the limitations of all block codes in a unified way. Such limitations often take the form of bounds that relate different parameters of the block code to each other, such as its rate and its ability to detect and correct errors.
Contents
- The block code and its parameters
- The alphabet
- The message length k
- The block length n
- The rate R
- The distance d
- Popular notation
- Examples
- Error detection and correction properties
- Family of codes
- Hamming bound
- Singleton bound
- Plotkin bound
- GilbertVarshamov bound
- Johnson bound
- EliasBassalygo bound
- Sphere packings and lattices
- References
Examples of block codes are Reed–Solomon codes, Hamming codes, Hadamard codes, Expander codes, Golay codes, and Reed–Muller codes. These examples also belong to the class of linear codes, and hence they are called linear block codes. More particularly, these codes are known as algebraic block codes, or cyclic block codes, because they can be generated using boolean polynomials.
Algebraic block codes are typically hard-decoded using algebraic decoders.
The term block code may also refer to any error-correcting code that acts on a block of k bits of input data to produce n bits of output data (n,k). Consequently, the block coder is a memoryless device. Under this definition codes such as turbo codes, terminated convolutional codes and other iteratively decodable codes (turbo-like codes) would also be considered block codes. A non-terminated convolutional encoder would be an example of a non-block (unframed) code, which has memory and is instead classified as a tree code.
This article deals with "algebraic block codes".
The block code and its parameters
Error-correcting codes are used to reliably transmit digital data over unreliable communication channels subject to channel noise. When a sender wants to transmit a possibly very long data stream using a block code, the sender breaks the stream up into pieces of some fixed size. Each such piece is called message and the procedure given by the block code encodes each message individually into a codeword, also called a block in the context of block codes. The sender then transmits all blocks to the receiver, who can in turn use some decoding mechanism to (hopefully) recover the original messages from the possibly corrupted received blocks. The performance and success of the overall transmission depends on the parameters of the channel and the block code.
Formally, a block code is an injective mapping
Here,
The alphabet Σ
The data stream to be encoded is modeled as a string over some alphabet
The message length k
Messages are elements
The block length n
The block length
The rate R
The rate of a block code is defined as the ratio between its message length and its block length:
A large rate means that the amount of actual message per transmitted block is high. In this sense, the rate measures the transmission speed and the quantity
The distance d
The distance or minimum distance
Since any code has to be injective, any two codewords will disagree in at least one position, so the distance of any code is at least
A larger distance allows for more error correction and detection. For example, if we only consider errors that may change symbols of the sent codeword but never erase or add them, then the number of errors is the number of positions in which the sent codeword and the received word differ. A code with distance
Popular notation
The notation
Sometimes, especially for non-block codes, the notation
Examples
As mentioned above, there are a vast number of error-correcting codes that are actually block codes. The first error-correcting code was the Hamming(7,4)-code, developed by Richard W. Hamming in 1950. This code transforms a message consisting of 4 bits into a codeword of 7 bits by adding 3 parity bits. Hence this code is a block code. It turns out that it is also a linear code and that it has distance 3. In the shorthand notation above, this means that the Hamming(7,4)-code is a
Reed–Solomon codes are a family of
Error detection and correction properties
A codeword
Family of codes
Rate of family of codes
Relative distance of family of codes
To explore the relationship between
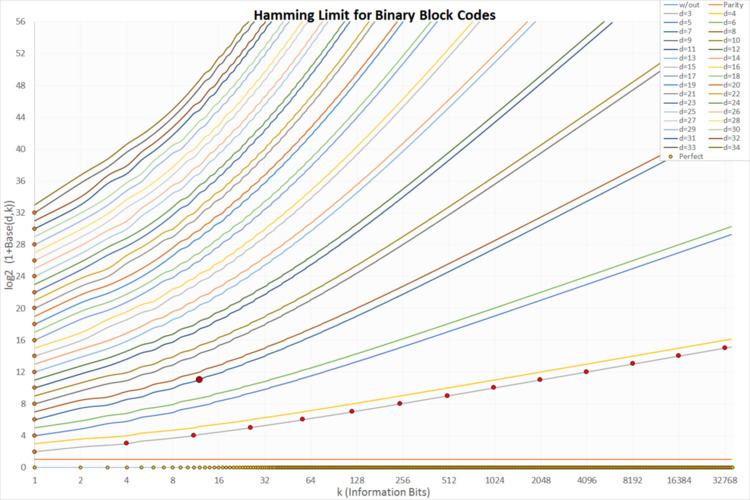
Hamming bound
Singleton bound
The Singleton bound is that the sum of the rate and the relative distance of a block code cannot be much larger than 1:
In other words, every block code satisfies the inequality
Plotkin bound
For
For the general case, the following Plotkin bounds holds for any
1. If
2. If
For any
Gilbert–Varshamov bound
Johnson bound
Define
Let
Then we have the Johnson Bound :
Elias–Bassalygo bound
Sphere packings and lattices
Block codes are tied to the sphere packing problem which has received some attention over the years. In two dimensions, it is easy to visualize. Take a bunch of pennies flat on the table and push them together. The result is a hexagon pattern like a bee's nest. But block codes rely on more dimensions which cannot easily be visualized. The powerful Golay code used in deep space communications uses 24 dimensions. If used as a binary code (which it usually is), the dimensions refer to the length of the codeword as defined above.
The theory of coding uses the N-dimensional sphere model. For example, how many pennies can be packed into a circle on a tabletop or in 3 dimensions, how many marbles can be packed into a globe. Other considerations enter the choice of a code. For example, hexagon packing into the constraint of a rectangular box will leave empty space at the corners. As the dimensions get larger, the percentage of empty space grows smaller. But at certain dimensions, the packing uses all the space and these codes are the so-called perfect codes. There are very few of these codes.
Another property is the number of neighbors a single codeword may have. Again, consider pennies as an example. First we pack the pennies in a rectangular grid. Each penny will have 4 near neighbors (and 4 at the corners which are farther away). In a hexagon, each penny will have 6 near neighbors. Respectively, in three and four dimensions, the maximum packing is given by the 12-face and 24-cell with 12 and 24 neighbors, respectively. When we increase the dimensions, the number of near neighbors increases very rapidly. In general, the value is given by the kissing numbers.
The result is that the number of ways for noise to make the receiver choose a neighbor (hence an error) grows as well. This is a fundamental limitation of block codes, and indeed all codes. It may be harder to cause an error to a single neighbor, but the number of neighbors can be large enough so the total error probability actually suffers.