
 | ||
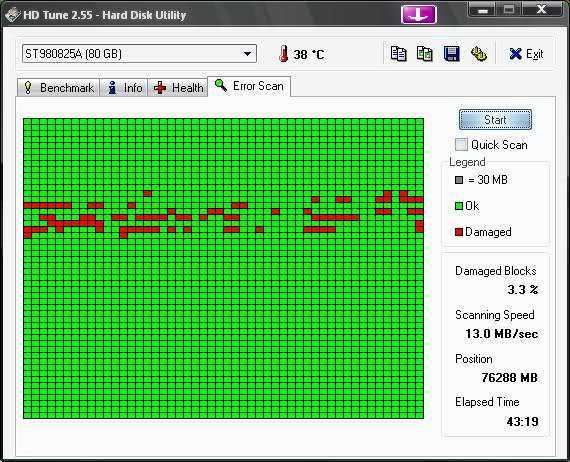
A bad sector is a sector on a computer's disk drive or flash memory that is either inaccessible or unwriteable due to permanent damage, such as physical damage to the disk surface or failed flash memory transistors. Bad sectors are usually detected by a disk utility software such as CHKDSK or SCANDISK on Microsoft systems, or badblocks on Unix-like systems. When found, these programs may mark the sectors unusable (most file systems contain provisions for bad-sector marks) and the operating system skips them in the future.
Contents
If any of the files uses a sector which is marked as 'bad' by a disk utility then the bad sector of the file is remapped to a free sector and any unreadable data is lost. To avoid file corruption data recovery methods should be performed first if bad sectors are found (before being marked) by OS at file system level.
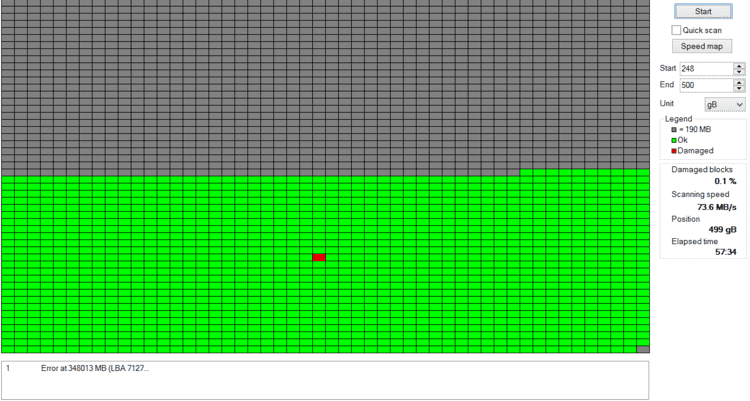
When a sector is found to be bad or unstable by the firmware of a disk controller, the disk controller remaps the logical sector to a different physical sector. In the normal operation of a hard drive, the detection and remapping of bad sectors should take place in a manner transparent to the rest of the system and in advance before data is lost. However, damage to the physical body of the hard drive does not solely affect one area of the data stored. Very often physical damages can interfere with parts of many different files.
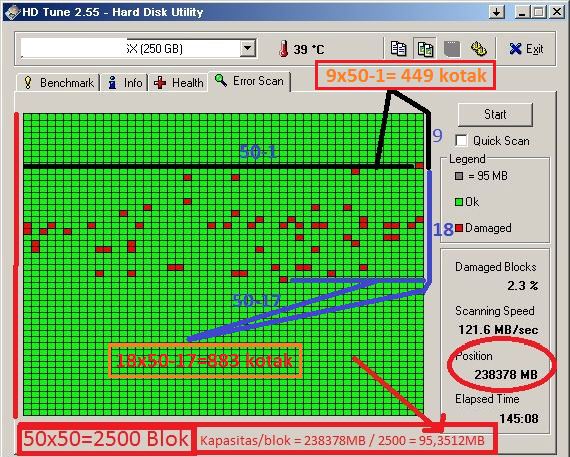
There are two types of remapping by disk hardware: P-LIST (Mapping during factory production tests) and G-LIST (Mapping during consumer usage by disk microcode).
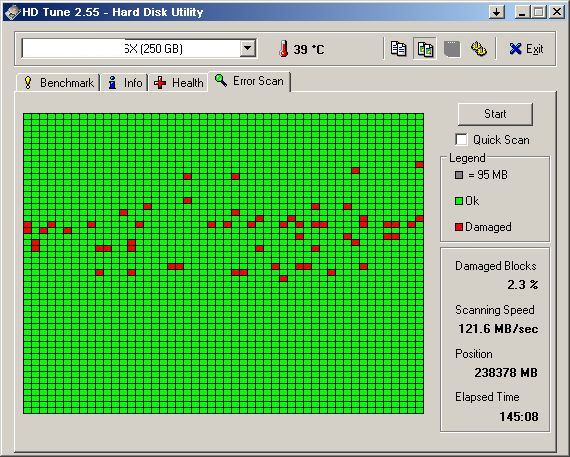
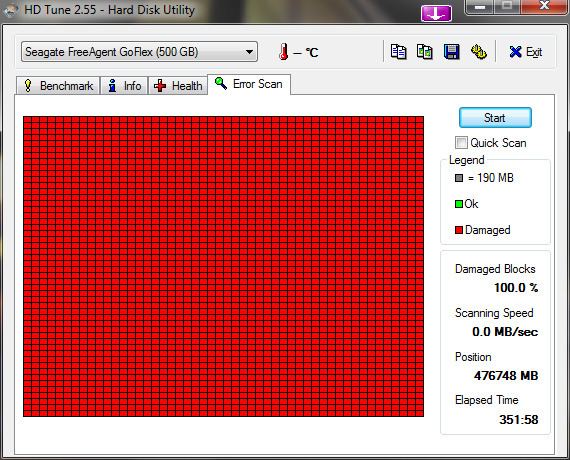
There are a variety of utilities that can read the Self-Monitoring, Analysis, and Reporting Technology (SMART) information to tell how many sectors have been reallocated, and how many spare sectors the drive may still have. Because reads and writes from G-list sectors are automatically redirected (remapped) to spare sectors it slows down drive access even if data in drive is defragmented. If the G-list is filling up, it is time to replace the drive.
Typically, automatic remapping of sectors only happens when a sector is written to. The logic behind this is presumably that even if a sector cannot be read normally, it may still be readable with data recovery methods. However, if a drive knows that a sector is bad and the drive's controller receives a command to write over it, it will not reuse that sector and will instead remap it to one of its spare-sector regions. This may be the reason why hard disks continue to have sector errors (mostly disk controller timeouts) until all the bad sectors are remapped; typically this is accomplished by writing zeros to the entire drive. See the SMART attribute number 197 ("Current Pending Sector Count") for more information.
Bad sector repair tool hdd head depopping
Copy protection
In the 1980s, many software vendors mass-produced floppy disks for distribution to users of home computers that had bad sectors deliberately introduced. The disk drives for these computers would not read the sector: the header information may be duplicated so that different data was read at each pass from different physical sectors with the same headers, or the data in the sector would not be read correctly by the head, and various other techniques described above. The home computer equipment could only write "good" sectors, so that attempts to copy the disk were flawed either because:
These techniques could generally be easily circumvented since the code to read the bad sectors was usually in the bootstrap loader on the disk itself, so by reverse engineering and rewriting the bootstrap loader, it would not look for the bad sectors, and the comparison for a known bit pattern would have to be encoded there, too.
Cracking
There were legitimate uses for doing so using a purchased disk as the master, and the hacked copy as the slave:
There are still legitimate reasons for use in software archaeology, where the original disk drives are rarely available, and modern computers run too fast to preserve the delicate timing characteristics these techniques often relied on.