
 | ||
Asymmetric Numeral Systems (ANS) is a family of entropy coding methods introduced by Jarek Duda, used in data compression since 2014 due to improved performance compared to the previously used methods: ANS combines the compression ratio of arithmetic coding (which uses nearly accurate probability distribution), with a processing cost similar to that of Huffman coding. In the tANS variant, this is achieved by constructing a finite state machine to operate on a large alphabet without using multiplication. Among others, ANS is used in the Facebook Zstandard compressor, in the Apple LZFSE compressor, Google Draco 3D compressor and in CRAM DNA compressor from popular SAMtools utilities.
Contents
- Entropy coding
- Basic concepts of ANS
- Uniform binary variant uABS
- Range variants rANS and streaming
- Tabled variant tANS
- Remarks
- References
The basic idea is to encode information into a single natural number
For the encoding rule, the set of natural numbers is split into disjoint subsets corresponding to different symbols - like into even and odd numbers, but with densities corresponding to the probability distribution of the symbols to encode. Then to add information from symbol
There are alternative ways to apply it in practice - direct mathematical formulas for encoding and decoding steps (uABS and rANS variants), or one can put the entire behavior into a table (tANS variant). Renormalization is used to prevent
Entropy coding
Imagine you want to encode a length 1000 sequence of zeros and ones, what directly takes 1000 bits to store. However, if it is somehow known that it only contains 1 zero and 999 ones, it would be sufficient to encode the zero position, what requires only
Generally, such length
Hence, to choose one of such sequences we need approximately
Entropy coder allows to encode a sequence of symbols using approximately Shannon entropy bits/symbol. For example ANS could be directly used to enumerate combinations: assign a different natural number to every sequence of symbols having fixed proportions in nearly optimal way.
In contrast to encoding combinations, this probability distribution usually varies in data compressors. For this purpose, Shannon entropy can be seen as weighted average: that symbol of probability
Basic concepts of ANS
Imagine there is some information stored in a natural number
The above procedure is optimal for uniform (symmetric) probability distribution of symbols
The coding function
Uniform binary variant (uABS)
Let us start with binary alphabet and probability distribution
Decoding:
Encoding:
For
Symbol
The
Imagine we would like to encode '0100' sequence starting from
Range variants (rANS) and streaming
Range variant also uses arithmetic formulas, but allows to operate on large alphabet. Intuitively, it divides the set of natural numbers into size
We start with quanization of probability distribution to
Denote
For
symbol(y) = s such that CDF[s] <= y < CDF[s+1] .
Now coding function is:
C(x,s) = (floor(x / f[s]) << n) + (x % f[s]) + CDF[s]
Decoding: s = symbol(x & mask)
D(x) = (f[s] * (x >> n) + (x & mask ) - CDF[s], s)
This way we can encode a sequence of symbols into a large natural number
In rANS variant
if(x < (1 << 16)) x = (x << 16) + read16bits()
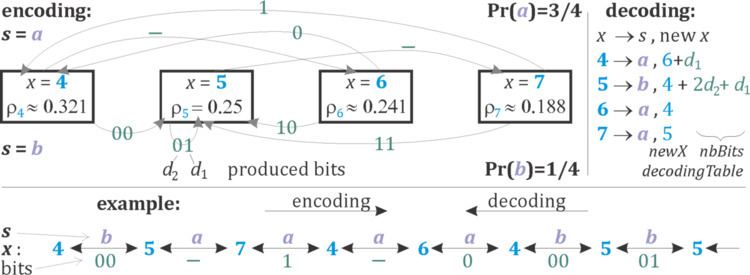
Tabled variant (tANS)
tANS variant puts the entire behavior (including renormalization) for
Finally step of decoding loop can be written as:
Step of encoding loop:
A specific tANS coding is determined by assigning a symbol to every
Remarks
As for Huffman coding, modifying the probability distribution of tANS is costly, hence they are used in static situations, usually with some Lempel–Ziv scheme (ZSTD, LZFSE). In this case, the file is divided into blocks and static probability distribution for each block is stored in its header.
In contrast, rANS is usually used as faster replacement for range coding. It requires multiplication, but is more memory efficient and is appropriate for dynamically adapting probability distributions.
Encoding and decoding of ANS are performed in opposite directions. This inconvenience is usually resolved by encoding in backward direction, thanks of it decoding can made forward. For context-dependence, like Markov model, the encoder needs to use context from the perspective of decoder. For adaptivity, the encoder should first go forward to find probabilities which will be used by decoder and store them in a buffer, then encode in backward direction using the found probabilities.
The final state of encoding is required to start decoding, hence it needs to be stored in the compressed file. This cost can be compensated by storing some information in the initial state of encoder.