
Designer ARM Holdings Design RISC | Bits 32-bit, 64-bit Type Register-Register | |
 | ||
Introduced 1985; 32 years ago (1985) Branching Condition code, compare and branch | ||
The arm university program arm architecture fundamentals
ARM, originally Acorn RISC Machine, later Advanced RISC Machine, is a family of reduced instruction set computing (RISC) architectures for computer processors, configured for various environments. British company ARM Holdings develops the architecture and licenses it to other companies, who design their own products that implement one of those architectures—
Contents
- The arm university program arm architecture fundamentals
- History
- Acorn RISC Machine ARM2
- Collaboration ARM6
- Early licencees
- Market share
- Core licence
- Architectural licence
- Cores
- Example applications of ARM cores
- 32 bit architecture
- CPU modes
- Instruction set
- Arithmetic instructions
- Registers
- Conditional execution
- Other features
- Pipelines and other implementation issues
- Coprocessors
- Debugging
- DSP enhancement instructions
- SIMD extensions for multimedia
- Jazelle
- Thumb
- Thumb 2
- Thumb Execution Environment ThumbEE
- Floating point VFP
- Advanced SIMD NEON
- TrustZone for Cortex A profile
- TrustZone for ARMv8 M For Cortex M Profile
- No execute page protection
- Large Physical Address Extension LPAE
- ARMv8 R and ARMv8 M
- ARMv8 A
- ARMv81 A
- ARMv82 A
- AArch64 features
- 32 bit operating systems
- 64 bit operating systems
- Porting to 32 or 64 bit ARM operating systems
- References
A RISC-based computer design approach means processors require fewer transistors than typical complex instruction set computing (CISC) x86 processors in most personal computers. This approach reduces costs, heat and power use. These characteristics are desirable for light, portable, battery-powered devices—
ARM Holdings periodically releases updates to its cores. All of them support a 32-bit address space (only pre-ARMv3 chips, made before ARM Holdings was formed, as in original Acorn Archimedes, had smaller) and 32-bit arithmetic; the ARMv8-A architecture, announced in October 2011, adds support for a 64-bit address space and 64-bit arithmetic. Instructions for ARM Holdings' cores have 32-bit fixed-length instructions, but later versions of the architecture also support a variable-length instruction set that provides both 32- and 16-bit instructions for improved code density. Some cores can also provide hardware execution of Java bytecodes.
With over 50 billion ARM processors produced as of 2014, ARM is the most widely used instruction set architecture in terms of quantity produced. Currently, the widely used Cortex cores, older "classic" cores, and specialized SecurCore cores variants are available for each of these to include or exclude optional capabilities.
History

The British computer manufacturer Acorn Computers first developed the Acorn RISC Machine architecture (ARM) in the 1980s to use in its personal computers. Its first ARM-based products were coprocessor modules for the BBC Micro series of computers. After the successful BBC Micro computer, Acorn Computers considered how to move on from the relatively simple MOS Technology 6502 processor to address business markets like the one that was soon dominated by the IBM PC, launched in 1981. The Acorn Business Computer (ABC) plan required that a number of second processors be made to work with the BBC Micro platform, but processors such as the Motorola 68000 and National Semiconductor 32016 were considered unsuitable, and the 6502 was not powerful enough for a graphics-based user interface.
According to Sophie Wilson, all the tested processors at that time performed about the same, with about a 4 Mbit/second bandwidth.
After testing all available processors and finding them lacking, Acorn decided it needed a new architecture. Inspired by white papers on the Berkeley RISC project, Acorn considered designing its own processor. A visit to the Western Design Center in Phoenix, where the 6502 was being updated by what was effectively a single-person company, showed Acorn engineers Steve Furber and Sophie Wilson they did not need massive resources and state-of-the-art research and development facilities.
Wilson developed the instruction set, writing a simulation of the processor in BBC BASIC that ran on a BBC Micro with a 6502 second processor. This convinced Acorn engineers they were on the right track. Wilson approached Acorn's CEO, Hermann Hauser, and requested more resources. Hauser gave his approval and assembled a small team to implement Wilson's model in hardware.
Acorn RISC Machine: ARM2
The official Acorn RISC Machine project started in October 1983. They chose VLSI Technology as the silicon partner, as they were a source of ROMs and custom chips for Acorn. Wilson and Furber led the design. They implemented it with a similar efficiency ethos as the 6502. A key design goal was achieving low-latency input/output (interrupt) handling like the 6502. The 6502's memory access architecture had let developers produce fast machines without costly direct memory access hardware.
The first samples of ARM silicon worked properly when first received and tested on 26 April 1985.
The first ARM application was as a second processor for the BBC Micro, where it helped in developing simulation software to finish development of the support chips (VIDC, IOC, MEMC), and sped up the CAD software used in ARM2 development. Wilson subsequently rewrote BBC BASIC in ARM assembly language. The in-depth knowledge gained from designing the instruction set enabled the code to be very dense, making ARM BBC BASIC an extremely good test for any ARM emulator. The original aim of a principally ARM-based computer was achieved in 1987 with the release of the Acorn Archimedes. In 1992, Acorn once more won the Queen's Award for Technology for the ARM.
The ARM2 featured a 32-bit data bus, 26-bit address space and 27 32 bit registers. Eight bits from the program counter register were available for other purposes; the top six bits (available because of the 26-bit address space) served as status flags, and the bottom two bits (available because the program counter was always word-aligned) were used for setting modes. The address bus was extended to 32 bits in the ARM6, but program code still had to lie within the first 64 MB of memory in 26-bit compatibility mode, due to the reserved bits for the status flags. The ARM2 had a transistor count of just 30,000, compared to Motorola's six-year-older 68000 model with around 40,000. Much of this simplicity came from the lack of microcode (which represents about one-quarter to one-third of the 68000) and from (like most CPUs of the day) not including any cache. This simplicity enabled low power consumption, yet better performance than the Intel 80286. A successor, ARM3, was produced with a 4 KB cache, which further improved performance.
Collaboration: ARM6
In the late 1980s Apple Computer and VLSI Technology started working with Acorn on newer versions of the ARM core. In 1990, Acorn spun off the design team into a new company named Advanced RISC Machines Ltd., which became ARM Ltd when its parent company, ARM Holdings plc, floated on the London Stock Exchange and NASDAQ in 1998. The new Apple-ARM work would eventually evolve into the ARM6, first released in early 1992. Apple used the ARM6-based ARM610 as the basis for their Apple Newton PDA.
Early licencees
In 1994, Acorn used the ARM610 as the main central processing unit (CPU) in their RiscPC computers. DEC licensed the ARM6 architecture and produced the StrongARM. At 233 MHz, this CPU drew only one watt (newer versions draw far less). This work was later passed to Intel as part of a lawsuit settlement, and Intel took the opportunity to supplement their i960 line with the StrongARM. Intel later developed its own high performance implementation named XScale, which it has since sold to Marvell. Transistor count of the ARM core remained essentially the same throughout these changes; ARM2 had 30,000 transistors, while ARM6 grew only to 35,000.
Market share
In 2005, about 98% of all mobile phones sold used at least one ARM processor. In 2010, producers of chips based on ARM architectures reported shipments of 6.1 billion ARM-based processors, representing 95% of smartphones, 35% of digital televisions and set-top boxes and 10% of mobile computers. In 2011, the 32-bit ARM architecture was the most widely used architecture in mobile devices and the most popular 32-bit one in embedded systems. In 2013, 10 billion were produced and "ARM-based chips are found in nearly 60 percent of the world’s mobile devices".
Core licence
ARM Holdings' primary business is selling IP cores, which licensees use to create microcontrollers (MCUs), CPUs, and systems-on-chips based on those cores. The original design manufacturer combines the ARM core with other parts to produce a complete device, typically one that can be built in existing Semiconductor fabrication plants (fabs) at low cost and still deliver substantial performance. The most successful implementation has been the ARM7TDMI with hundreds of millions sold. Atmel has been a precursor design center in the ARM7TDMI-based embedded system.
The ARM architectures used in smartphones, PDAs and other mobile devices range from ARMv5 to ARMv7-A, used in low-end and midrange devices, to ARMv8-A used in current high-end devices.
In 2009, some manufacturers introduced netbooks based on ARM architecture CPUs, in direct competition with netbooks based on Intel Atom. According to analyst firm IHS iSuppli, by 2015, ARM Integrated circuits may be in 23% of all laptops.
ARM Holdings offers a variety of licensing terms, varying in cost and deliverables. ARM Holdings provides to all licensees an integratable hardware description of the ARM core as well as complete software development toolset (compiler, debugger, software development kit) and the right to sell manufactured silicon containing the ARM CPU.
SoC packages integrating ARM's core designs include Nvidia Tegra's first three generations, CSR plc's Quatro family, ST-Ericsson's Nova and NovaThor, Silicon Labs's Precision32 MCU, Texas Instruments's OMAP products, Samsung's Hummingbird and Exynos products, Apple's A4, A5, and A5X, and Freescale's i.MX.
Fabless licensees, who wish to integrate an ARM core into their own chip design, are usually only interested in acquiring a ready-to-manufacture verified IP core. For these customers, ARM Holdings delivers a gate netlist description of the chosen ARM core, along with an abstracted simulation model and test programs to aid design integration and verification. More ambitious customers, including integrated device manufacturers (IDM) and foundry operators, choose to acquire the processor IP in synthesizable RTL (Verilog) form. With the synthesizable RTL, the customer has the ability to perform architectural level optimisations and extensions. This allows the designer to achieve exotic design goals not otherwise possible with an unmodified netlist (high clock speed, very low power consumption, instruction set extensions, etc.). While ARM Holdings does not grant the licensee the right to resell the ARM architecture itself, licensees may freely sell manufactured product such as chip devices, evaluation boards and complete systems. Merchant foundries can be a special case; not only are they allowed to sell finished silicon containing ARM cores, they generally hold the right to re-manufacture ARM cores for other customers.
ARM Holdings prices its IP based on perceived value. Lower performing ARM cores typically have lower licence costs than higher performing cores. In implementation terms, a synthesizable core costs more than a hard macro (blackbox) core. Complicating price matters, a merchant foundry that holds an ARM licence, such as Samsung or Fujitsu, can offer fab customers reduced licensing costs. In exchange for acquiring the ARM core through the foundry's in-house design services, the customer can reduce or eliminate payment of ARM's upfront licence fee.
Compared to dedicated semiconductor foundries (such as TSMC and UMC) without in-house design services, Fujitsu/Samsung charge two- to three-times more per manufactured wafer. For low to mid volume applications, a design service foundry offers lower overall pricing (through subsidisation of the licence fee). For high volume mass-produced parts, the long term cost reduction achievable through lower wafer pricing reduces the impact of ARM's NRE (Non-Recurring Engineering) costs, making the dedicated foundry a better choice.
Companies that have designed chips with ARM cores include Amazon.com's Annapurna Labs subsidiary, Analog Devices, Apple, AppliedMicro, Atmel, Broadcom, Cypress Semiconductor, Freescale Semiconductor (now NXP Semiconductors), Nvidia, NXP, Qualcomm, Renesas, Samsung Electronics, ST Microelectronics and Texas Instruments.
Architectural licence
Companies can also obtain an ARM architectural licence for designing their own CPU cores using the ARM instruction sets. These cores must comply fully with the ARM architecture. Companies that have designed cores that implement an ARM architecture include Apple, AppliedMicro, Broadcom, Cavium, Nvidia, Qualcomm, and Samsung Electronics.
Cores
ARM Holdings provides a list of vendors who implement ARM cores in their design (application specific standard products (ASSP), microprocessor and microcontrollers).
Example applications of ARM cores
ARM cores are used in a number of products, particularly PDAs and smartphones. Some computing examples are Microsoft's first generation Surface and Surface 2, Apple's iPads, and Asus's Eee Pad Transformer tablet computers. Others include Apple's iPhone smartphone and iPod portable media player, Canon PowerShot digital cameras, Nintendo DS handheld game consoles and TomTom turn-by-turn navigation systems.
In 2005, ARM Holdings took part in the development of Manchester University's computer SpiNNaker, which used ARM cores to simulate the human brain.
ARM chips are also used in Raspberry Pi, BeagleBoard, BeagleBone, PandaBoard and other single-board computers, because they are very small, inexpensive and consume very little power.
32-bit architecture
The 32-bit ARM architecture, such as ARMv7-A, is the most widely used architecture in mobile devices.
Since 1995, the ARM Architecture Reference Manual has been the primary source of documentation on the ARM processor architecture and instruction set, distinguishing interfaces that all ARM processors are required to support (such as instruction semantics) from implementation details that may vary. The architecture has evolved over time, and version seven of the architecture, ARMv7, defines three architecture "profiles":
Although the architecture profiles were first defined for ARMv7, ARM subsequently defined the ARMv6-M architecture (used by the Cortex M0/M0+/M1) as a subset of the ARMv7-M profile with fewer instructions.
CPU modes
Except in the M-profile, the 32-bit ARM architecture specifies several CPU modes, depending on the implemented architecture features. At any moment in time, the CPU can be in only one mode, but it can switch modes due to external events (interrupts) or programmatically.
Instruction set
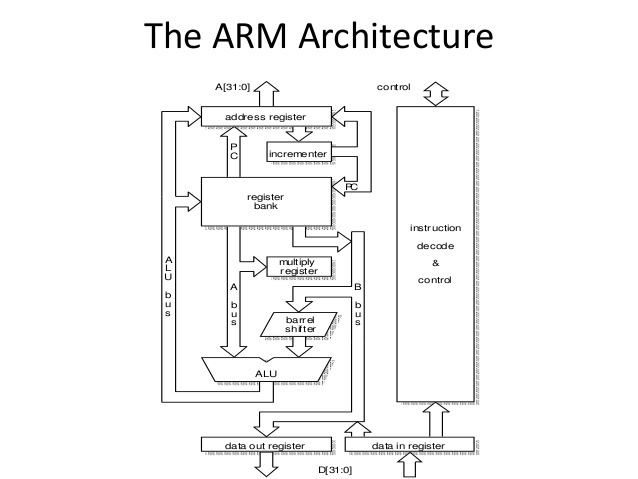
The original (and subsequent) ARM implementation was hardwired without microcode, like the much simpler 8-bit 6502 processor used in prior Acorn microcomputers.
The 32-bit ARM architecture (and the 64-bit architecture for the most part) includes the following RISC features:
To compensate for the simpler design, compared with processors like the Intel 80286 and Motorola 68020, some additional design features were used:
Arithmetic instructions
ARM includes integer arithmetic operations for add, subtract, and multiply; some versions of the architecture also support divide operations.
ARM supports 32-bit x 32-bit multiplies with either a 32-bit result or 64-bit result, though Cortex-M0 / M0+ / M1 cores don't support 64-bit results. Some ARM cores also support 16-bit x 16-bit and 32-bit x 16-bit multiplies.
The divide instructions are only included in the following ARM architectures:
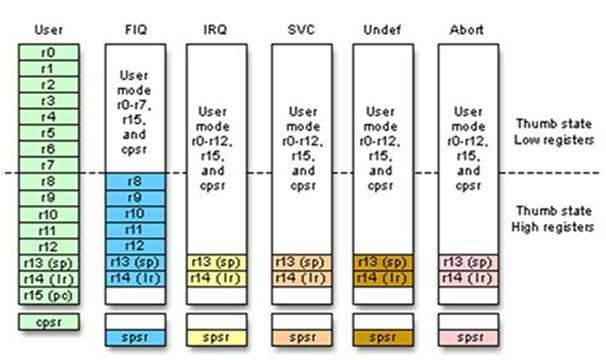
Registers
Registers R0 through R7 are the same across all CPU modes; they are never banked.
Registers R8 through R12 are the same across all CPU modes except FIQ mode. FIQ mode has its own distinct R8 through R12 registers.
R13 and R14 are banked across all privileged CPU modes except system mode. That is, each mode that can be entered because of an exception has its own R13 and R14. These registers generally contain the stack pointer and the return address from function calls, respectively.
Aliases:
The Current Program Status Register (CPSR) has the following 32 bits.
Conditional execution
Almost every ARM instruction has a conditional execution feature called predication, which is implemented with a 4-bit condition code selector (the predicate). To allow for unconditional execution, one of the four-bit codes causes the instruction to be always executed. Most other CPU architectures only have condition codes on branch instructions.
Though the predicate takes up four of the 32 bits in an instruction code, and thus cuts down significantly on the encoding bits available for displacements in memory access instructions, it avoids branch instructions when generating code for small if statements. Apart from eliminating the branch instructions themselves, this preserves the fetch/decode/execute pipeline at the cost of only one cycle per skipped instruction.
The standard example of conditional execution is the subtraction-based Euclidean algorithm:
In the C programming language, the loop is:
For ARM assembly, the loop can be effectively transformed into:
and coded as:
which avoids the branches around the then and else clauses. If Ri and Rj are equal then neither of the SUB instructions will be executed, eliminating the need for a conditional branch to implement the while check at the top of the loop, for example had SUBLE (less than or equal) been used.
One of the ways that Thumb code provides a more dense encoding is to remove the four bit selector from non-branch instructions.
Other features
Another feature of the instruction set is the ability to fold shifts and rotates into the "data processing" (arithmetic, logical, and register-register move) instructions, so that, for example, the C statement
could be rendered as a single-word, single-cycle instruction:
This results in the typical ARM program being denser than expected with fewer memory accesses; thus the pipeline is used more efficiently.
The ARM processor also has features rarely seen in other RISC architectures, such as PC-relative addressing (indeed, on the 32-bit ARM the PC is one of its 16 registers) and pre- and post-increment addressing modes.
The ARM instruction set has increased over time. Some early ARM processors (before ARM7TDMI), for example, have no instruction to store a two-byte quantity.
Pipelines and other implementation issues
The ARM7 and earlier implementations have a three-stage pipeline; the stages being fetch, decode and execute. Higher-performance designs, such as the ARM9, have deeper pipelines: Cortex-A8 has thirteen stages. Additional implementation changes for higher performance include a faster adder and more extensive branch prediction logic. The difference between the ARM7DI and ARM7DMI cores, for example, was an improved multiplier; hence the added "M".
Coprocessors
The ARM architecture (pre-ARMv8) provides a non-intrusive way of extending the instruction set using "coprocessors" that can be addressed using MCR, MRC, MRRC, MCRR and similar instructions. The coprocessor space is divided logically into 16 coprocessors with numbers from 0 to 15, coprocessor 15 (cp15) being reserved for some typical control functions like managing the caches and MMU operation on processors that have one.
In ARM-based machines, peripheral devices are usually attached to the processor by mapping their physical registers into ARM memory space, into the coprocessor space, or by connecting to another device (a bus) that in turn attaches to the processor. Coprocessor accesses have lower latency, so some peripherals—for example, an XScale interrupt controller—are accessible in both ways: through memory and through coprocessors.
In other cases, chip designers only integrate hardware using the coprocessor mechanism. For example, an image processing engine might be a small ARM7TDMI core combined with a coprocessor that has specialised operations to support a specific set of HDTV transcoding primitives.
Debugging
All modern ARM processors include hardware debugging facilities, allowing software debuggers to perform operations such as halting, stepping, and breakpointing of code starting from reset. These facilities are built using JTAG support, though some newer cores optionally support ARM's own two-wire "SWD" protocol. In ARM7TDMI cores, the "D" represented JTAG debug support, and the "I" represented presence of an "EmbeddedICE" debug module. For ARM7 and ARM9 core generations, EmbeddedICE over JTAG was a de facto debug standard, though not architecturally guaranteed.
The ARMv7 architecture defines basic debug facilities at an architectural level. These include breakpoints, watchpoints and instruction execution in a "Debug Mode"; similar facilities were also available with EmbeddedICE. Both "halt mode" and "monitor" mode debugging are supported. The actual transport mechanism used to access the debug facilities is not architecturally specified, but implementations generally include JTAG support.
There is a separate ARM "CoreSight" debug architecture, which is not architecturally required by ARMv7 processors.
DSP enhancement instructions
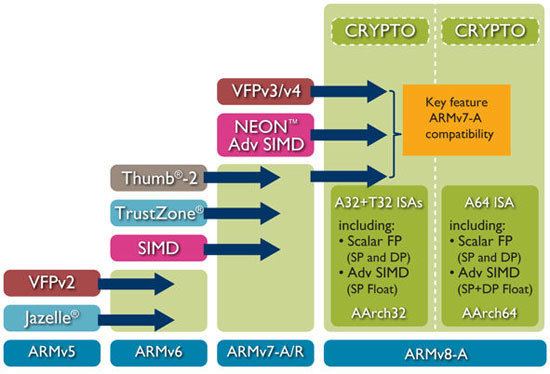
To improve the ARM architecture for digital signal processing and multimedia applications, DSP instructions were added to the set. These are signified by an "E" in the name of the ARMv5TE and ARMv5TEJ architectures. E-variants also imply T, D, M and I.
The new instructions are common in digital signal processor (DSP) architectures. They include variations on signed multiply–accumulate, saturated add and subtract, and count leading zeros.
SIMD extensions for multimedia
Introduced in the ARMv6 architecture, this was a precursor to Advanced SIMD, also known as NEON.
Jazelle
Jazelle DBX (Direct Bytecode eXecution) is a technique that allows Java Bytecode to be executed directly in the ARM architecture as a third execution state (and instruction set) alongside the existing ARM and Thumb-mode. Support for this state is signified by the "J" in the ARMv5TEJ architecture, and in ARM9EJ-S and ARM7EJ-S core names. Support for this state is required starting in ARMv6 (except for the ARMv7-M profile), though newer cores only include a trivial implementation that provides no hardware acceleration.
Thumb
To improve compiled code-density, processors since the ARM7TDMI (released in 1994) have featured the Thumb instruction set, which have their own state. (The "T" in "TDMI" indicates the Thumb feature.) When in this state, the processor executes the Thumb instruction set, a compact 16-bit encoding for a subset of the ARM instruction set. Most of the Thumb instructions are directly mapped to normal ARM instructions. The space-saving comes from making some of the instruction operands implicit and limiting the number of possibilities compared to the ARM instructions executed in the ARM instruction set state.
In Thumb, the 16-bit opcodes have less functionality. For example, only branches can be conditional, and many opcodes are restricted to accessing only half of all of the CPU's general-purpose registers. The shorter opcodes give improved code density overall, even though some operations require extra instructions. In situations where the memory port or bus width is constrained to less than 32 bits, the shorter Thumb opcodes allow increased performance compared with 32-bit ARM code, as less program code may need to be loaded into the processor over the constrained memory bandwidth.
Embedded hardware, such as the Game Boy Advance, typically have a small amount of RAM accessible with a full 32-bit datapath; the majority is accessed via a 16-bit or narrower secondary datapath. In this situation, it usually makes sense to compile Thumb code and hand-optimise a few of the most CPU-intensive sections using full 32-bit ARM instructions, placing these wider instructions into the 32-bit bus accessible memory.
The first processor with a Thumb instruction decoder was the ARM7TDMI. All ARM9 and later families, including XScale, have included a Thumb instruction decoder. The Thumb instruction set was originally inspired by SuperH's ISA; ARM licensed several patents from Hitachi.
Thumb-2
Thumb-2 technology was introduced in the ARM1156 core, announced in 2003. Thumb-2 extends the limited 16-bit instruction set of Thumb with additional 32-bit instructions to give the instruction set more breadth, thus producing a variable-length instruction set. A stated aim for Thumb-2 was to achieve code density similar to Thumb with performance similar to the ARM instruction set on 32-bit memory.
Thumb-2 extends the Thumb instruction set with bit-field manipulation, table branches and conditional execution. At the same time, the ARM instruction set was extended to maintain equivalent functionality in both instruction sets. A new "Unified Assembly Language" (UAL) supports generation of either Thumb or ARM instructions from the same source code; versions of Thumb seen on ARMv7 processors are essentially as capable as ARM code (including the ability to write interrupt handlers). This requires a bit of care, and use of a new "IT" (if-then) instruction, which permits up to four successive instructions to execute based on a tested condition, or on its inverse. When compiling into ARM code, this is ignored, but when compiling into Thumb it generates an actual instruction. For example:
All ARMv7 chips support the Thumb instruction set. All chips in the Cortex-A series, Cortex-R series, and ARM11 series support both "ARM instruction set state" and "Thumb instruction set state", while chips in the Cortex-M series support only the Thumb instruction set.
Thumb Execution Environment (ThumbEE)
ThumbEE (erroneously called Thumb-2EE in some ARM documentation), marketed as Jazelle RCT (Runtime Compilation Target), was announced in 2005, first appearing in the Cortex-A8 processor. ThumbEE is a fourth instruction set state, making small changes to the Thumb-2 extended instruction set. These changes make the instruction set particularly suited to code generated at runtime (e.g. by JIT compilation) in managed Execution Environments. ThumbEE is a target for languages such as Java, C#, Perl, and Python, and allows JIT compilers to output smaller compiled code without impacting performance.
New features provided by ThumbEE include automatic null pointer checks on every load and store instruction, an instruction to perform an array bounds check, and special instructions that call a handler. In addition, because it utilises Thumb-2 technology, ThumbEE provides access to registers r8-r15 (where the Jazelle/DBX Java VM state is held). Handlers are small sections of frequently called code, commonly used to implement high level languages, such as allocating memory for a new object. These changes come from repurposing a handful of opcodes, and knowing the core is in the new ThumbEE state.
On 23 November 2011, ARM Holdings deprecated any use of the ThumbEE instruction set, and ARMv8 removes support for ThumbEE.
Floating-point (VFP)
VFP (Vector Floating Point) technology is an FPU (Floating-Point Unit) coprocessor extension to the ARM architecture (implemented differently in ARMv8 - coprocessors not defined there). It provides low-cost single-precision and double-precision floating-point computation fully compliant with the ANSI/IEEE Std 754-1985 Standard for Binary Floating-Point Arithmetic. VFP provides floating-point computation suitable for a wide spectrum of applications such as PDAs, smartphones, voice compression and decompression, three-dimensional graphics and digital audio, printers, set-top boxes, and automotive applications. The VFP architecture was intended to support execution of short "vector mode" instructions but these operated on each vector element sequentially and thus did not offer the performance of true single instruction, multiple data (SIMD) vector parallelism. This vector mode was therefore removed shortly after its introduction, to be replaced with the much more powerful NEON Advanced SIMD unit.
Some devices such as the ARM Cortex-A8 have a cut-down VFPLite module instead of a full VFP module, and require roughly ten times more clock cycles per float operation. Pre-ARMv8 architecture implemented floating-point/SIMD with the coprocessor interface. Other floating-point and/or SIMD units found in ARM-based processors using the coprocessor interface include FPA, FPE, iwMMXt, some of which were implemented in software by trapping but could have been implemented in hardware. They provide some of the same functionality as VFP but are not opcode-compatible with it.
In Debian Linux, and derivatives such as Ubuntu, armhf (ARM hard float) refers to the ARMv7 architecture including the additional VFP3-D16 floating-point hardware extension (and Thumb-2) above. Software packages and cross-compiler tools use the armhf vs. arm/armel suffixes to differentiate.
Advanced SIMD (NEON)
The Advanced SIMD extension (aka NEON or "MPE" Media Processing Engine) is a combined 64- and 128-bit SIMD instruction set that provides standardized acceleration for media and signal processing applications. NEON is included in all Cortex-A8 devices but is optional in Cortex-A9 devices. NEON can execute MP3 audio decoding on CPUs running at 10 MHz and can run the GSM adaptive multi-rate (AMR) speech codec at no more than 13 MHz. It features a comprehensive instruction set, separate register files and independent execution hardware. NEON supports 8-, 16-, 32- and 64-bit integer and single-precision (32-bit) floating-point data and SIMD operations for handling audio and video processing as well as graphics and gaming processing. In NEON, the SIMD supports up to 16 operations at the same time. The NEON hardware shares the same floating-point registers as used in VFP. Devices such as the ARM Cortex-A8 and Cortex-A9 support 128-bit vectors but will execute with 64 bits at a time, whereas newer Cortex-A15 devices can execute 128 bits at a time.
ProjectNe10 is ARM's first open source project (from its inception). The Ne10 library is a set of common, useful functions written in both NEON and C (for compatibility). The library was created to allow developers to use NEON optimisations without learning NEON but it also serves as a set of highly optimised NEON intrinsic and assembly code examples for common DSP, arithmetic and image processing routines. The code is available on GitHub.
TrustZone (for Cortex-A profile)
The Security Extensions, marketed as TrustZone Technology, is in ARMv6KZ and later application profile architectures. It provides a low-cost alternative to adding another dedicated security core to an SoC, by providing two virtual processors backed by hardware based access control. This lets the application core switch between two states, referred to as worlds (to reduce confusion with other names for capability domains), in order to prevent information from leaking from the more trusted world to the less trusted world. This world switch is generally orthogonal to all other capabilities of the processor, thus each world can operate independently of the other while using the same core. Memory and peripherals are then made aware of the operating world of the core and may use this to provide access control to secrets and code on the device.
Typically, a rich operating system is run in the less trusted world, with smaller security-specialized code in the more trusted world, aiming to reduce the attack surface. Typical applications include DRM functionality for controlling the use of media on ARM-based devices, and preventing any unapproved use of the device.
One option for the more trusted world is TrustZone Software, a TrustZone optimised version of the Trusted Foundations Software developed by Trusted Logic Mobility. Trusted Foundations Software was acquired by Gemalto. Giesecke & Devrient developed a rival implementation named Mobicore. In April 2012 ARM Gemalto and Giesecke & Devrient combined their TrustZone portfolios into a joint venture Trustonic.
In practice, since the specific implementation details of proprietary TrustZone implementations have not been publicly disclosed for review, it is unclear what level of assurance is provided for a given threat model, but they are not immune from attack.
Open Virtualization and T6 are open source implementations of the trusted world architecture for TrustZone.
AMD has licensed and incorprorated TrustZone technology into its Secure Processor Technology. Enabled in some but not all products, AMD's APUs include a Cortex-A5 processor for handling secure processing. In fact, the Cortex-A5 TrustZone core had been included in earlier AMD products, but was not enabled due to time constraints.
Samsung Knox uses TrustZone for purposes such as detecting modifications to the kernel.
TrustZone for ARMv8-M (For Cortex-M Profile)
The Security Extension, marketed as TrustZone for ARMv8-M Technology, was introduced in the ARMv8-M architecture.
No-execute page protection
As of ARMv6, the ARM architecture supports no-execute page protection, which is referred to as XN, for eXecute Never.
Large Physical Address Extension (LPAE)
The Large Physical Address Extension (LPAE), which extends the physical address size from 32 bits to 40 bits, was added to the ARMv7-A architecture in 2011.
ARMv8-R and ARMv8-M
The ARMv8-R and ARMv8-M sub-architectures, announced after the ARMv8-A, share some features with ARMv8-A, but are not 64-bit.
ARMv8-A
Announced in October 2011, ARMv8-A (often called ARMv8 while the ARMv8-R is also available) represents a fundamental change to the ARM architecture. It adds an optional 64-bit architecture (e.g. Cortex-A32 is a 32-bit ARMv8-A CPU while most ARMv8-A CPUs support 64-bit, unlike all ARMv8-R), named "AArch64", and the associated new "A64" instruction set. AArch64 provides user-space compatibility with ARMv7-A, the 32-bit architecture, therein referred to as "AArch32" and the old 32-bit instruction set, now named "A32". The Thumb instruction sets are referred to as "T32" and have no 64-bit counterpart. ARMv8-A allows 32-bit applications to be executed in a 64-bit OS, and a 32-bit OS to be under the control of a 64-bit hypervisor. ARM announced their Cortex-A53 and Cortex-A57 cores on 30 October 2012. Apple was the first to release an ARMv8-A compatible core (Apple A7) in a consumer product (iPhone 5S). AppliedMicro, using an FPGA, was the first to demo ARMv8-A. The first ARMv8-A SoC from Samsung is the Exynos 5433 in the Galaxy Note 4, which features two clusters of four Cortex-A57 and Cortex-A53 cores in a big.LITTLE configuration; but it will run only in AArch32 mode.
To both AArch32 and AArch64, ARMv8-A makes VFPv3/v4 and advanced SIMD (NEON) standard. It also adds cryptography instructions supporting AES, SHA-1/SHA-256 and finite field arithmetic.
ARMv8.1-A
In December 2014, ARMv8.1-A, an update with "incremental benefits over v8.0", was announced. The enhancements fell into two categories: changes to the instruction set, and changes to the exception model and memory translation.
Instruction set enhancements included the following:
Enhancements for the exception model and memory translation system included the following:
ARMv8-A code will run on v8.1 cores.
ARMv8.2-A
In January 2016, ARMv8.2-A was announced. Its enhancements fell into four categories: