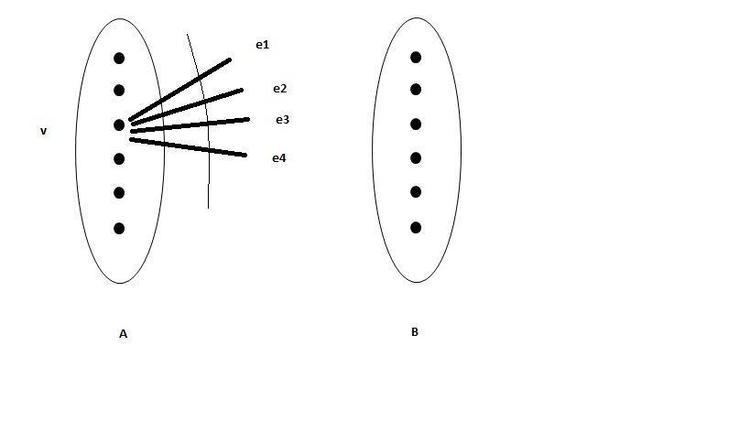
Zemor's algorithm is based on a type of expander graphs called Tanner graph. The construction of code was first proposed by Tanner. The codes are based on double cover d , regular expander G , which is a bipartite graph. G = ( V , E ) , where V is the set of vertices and E is the set of edges and V = A ∪ B and A ∩ B = ∅ , where A and B denotes the set of 2 vertices. Let n be the number of vertices in each group, i.e, | A | = | B | = n . The edge set E be of size N = n d and every edge in E has one endpoint in both A and B . E ( v ) denotes the set of edges containing v .
Assume an ordering on V , therefore ordering will be done on every edges of E ( v ) for every v ∈ V . Let finite field F = G F ( 2 ) , and for a word x = ( x e ) , e ∈ E in F N , let the subword of the word will be indexed by E ( v ) . Let that word be denoted by ( x ) v . The subset of vertices A and B induces every word x ∈ F N a partition into n non-overlapping sub-words ( x ) v ∈ F d , where v ranges over the elements of A . For constructing a code C , consider a linear subcode C o , which is a [ d , r o d , δ ] code, where q , the size of the alphabet is 2 . For any vertex v ∈ V , let v ( 1 ) , v ( 2 ) , … , v ( d ) be some ordering of the d vertices of E adjacent to v . In this code, each bit x e is linked with an edge e of E .
We can define the code C to be the set of binary vectors x = ( x 1 , x 2 , … , x N ) of { 0 , 1 } N such that, for every vertex v of V , ( x v ( 1 ) , x v ( 2 ) , … , x v ( d ) ) is a code word of C o . In this case, we can consider a special case when every vertex of E is adjacent to exactly 2 vertices of V . It means that V and E make up, respectively, the vertex set and edge set of d regular graph G .
Let us call the code C constructed in this way as ( G , C o ) code. For a given graph G and a given code C o , there are several ( G , C o ) codes as there are different ways of ordering edges incident to a given vertex v , i.e., v ( 1 ) , v ( 2 ) , … , v ( d ) . In fact our code C consist of all codewords such that x v ∈ C o for all v ∈ A , B . The code C is linear [ N , K , D ] in F as it is generated from a subcode C o , which is linear. The code C is defined as C = { c ∈ F N : ( c ) v ∈ C o } for every v ∈ V .
In this figure, ( x ) v = ( x e 1 , x e 2 , x e 3 , x e 4 ) ∈ C o . It shows the graph G and code C .
In matrix G , let λ is equal to the second largest eigen value of adjacency matrix of G . Here the largest eigen value is d . Two important claims are made:
( K N ) ≥ 2 r o − 1
. Let R be the rate of a linear code constructed from a bipartite graph whose digit nodes have degree m and whose subcode nodes have degree n . If a single linear code with parameters ( n , k ) and rate r = ( k n ) is associated with each of the subcode nodes, then k ≥ 1 − ( 1 − r ) m .
Let R be the rate of the linear code, which is equal to K / N Let there are S subcode nodes in the graph. If the degree of the subcode is n , then the code must have ( n m ) S digits, as each digit node is connected to m of the ( n ) S edges in the graph. Each subcode node contributes ( n − k ) equations to parity check matrix for a total of ( n − k ) S . These equations may not be linearly independent. Therefore, ( K N ) ≥ ( ( n m ) S − ( n − k ) S ( n m ) S )
≥ 1 − m ( n − k n )
≥ 1 − m ( 1 − r ) , Since the value of m ,i.e., the digit node of this bipartite graph is 2 and here r = r o , we can write as:
( K N ) ≥ 2 r o − 1
D ≥ N ( ( δ − ( λ d ) ) ( 1 − ( λ d ) ) ) 2 = N ( δ 2 − O ( λ d ) ) → ( 1 ) If S is linear code of rate r , block code length d , and minimum relative distance δ , and if B is the edge vertex incidence graph of a d – regular graph with second largest eigen value λ , then the code C ( B , S ) has rate at least 2 r o − 1 and minimum relative distance at least ( ( δ − ( λ d ) 1 − ( λ d ) ) ) 2 .
Let B be derived from the d regular graph G . So, the number of variables of C ( B , S ) is ( d n 2 ) and the number of constraints is n . According to Alon - Chung, if X is a subset of vertices of G of size γ n , then the number of edges contained in the subgraph is induced by X in G is at most ( d n 2 ) ( γ 2 + ( λ d ) γ ( 1 − γ ) ) .
As a result, any set of ( d n 2 ) ( γ 2 + ( λ d ) γ ( 1 − γ ) ) variables will be having at least γ n constraints as neighbours. So the average number of variables per constraint is : ( ( 2 n d 2 ) ( γ 2 + ( λ d ) γ ( 1 − γ ) ) γ n ) = d ( γ + ( λ d ) ( 1 − γ ) ) → ( 2 )
So if d ( γ + ( λ d ) ( 1 − γ ) ) < γ d , then a word of relative weight ( γ 2 + ( λ d ) γ ( 1 − γ ) ) , cannot be a codeword of C ( B , S ) . The inequality ( 2 ) is satisfied for γ < ( 1 − ( λ d ) δ − ( λ d ) ) . Therefore, C ( B , S ) cannot have a non zero codeword of relative weight ( δ − ( λ d ) 1 − ( λ d ) ) 2 or less.
In matrix G , we can assume that λ / d is bounded away from 1 . For those values of d in which d − 1 is odd prime, there are explicit constructions of sequences of d - regular bipartite graphs with arbitrarily large number of vertices such that each graph G in the sequence is a Ramanujan graph. It is called Ramanujan graph as it satisfies the inequality λ ( G ) ≤ 2 d − 1 . Certain expansion properties are visible in graph G as the separation between the eigen values d and λ . If the graph G is Ramanujan graph, then that expression ( 1 ) will become 0 eventually as d becomes large.
The iterative decoding algorithm written below alternates between the vertices A and B in G and corrects the codeword of C o in A and then it switches to correct the codeword C o in B . Here edges associated with a vertex on one side of a graph are not incident to other vertex on that side. In fact, it doesn't matter in which order, the set of nodes A and B are processed. The vertex processing can also be done in parallel.
The decoder D : F d → C o stands for a decoder for C o that recovers correctly with any codewords with less than ( d 2 ) errors.
Received word : w = ( w e ) , e ∈ E
z ← w
For t ← 1 to m do // m is the number of iterations
{ if ( t is odd) // Here the algorithm will alternate between its two vertex sets.
X ← A
else X ← B
Iteration t : For every v ∈ X , let ( z ) v ← D ( ( z ) v ) // Decoding z v to its nearest codeword.
}
Output: z
Since G is bipartite, the set A of vertices induces the partition of the edge set E = ∪ v ∈ A E v . The set B induces another partition, E = ∪ v ∈ B E v .
Let w ∈ { 0 , 1 } N be the received vector, and recall that N = d n . The first iteration of the algorithm consists of applying the complete decoding for the code induced by E v for every v ∈ A . This means that for replacing, for every v ∈ A , the vector ( w v ( 1 ) , w v ( 2 ) , … , w v ( d ) ) by one of the closest codewords of C o . Since the subsets of edges E v are disjoint for v ∈ A , the decoding of these n subvectors of w may be done in parallel.
The iteration will yield a new vector z . The next iteration consists of applying the preceding procedure to z but with A replaced by B . In other words, it consists of decoding all the subvectors induced by the vertices of B . The coming iterations repeat those two steps alternately applying parallel decoding to the subvectors induced by the vertices of A and to the subvectors induced by the vertices of B .
Note: [If d = n and G is the complete bipartite graph, then C is a product code of C o with itself and the above algorithm reduces to the natural hard iterative decoding of product codes].
Here, the number of iterations, m is ( ( log n ) log ( 2 − α ) ) . In general, the above algorithm can correct a code word whose Hamming weight is no more than ( 1 2 ) . α N δ ( ( δ 2 ) − ( λ d ) ) = ( ( 1 4 ) . α N ( δ 2 − O ( λ d ) ) for values of α < 1 . Here, the decoding algorithm is implemented as a circuit of size O ( N log N ) and depth O ( log N ) that returns the codeword given that error vector has weight less than α N δ 2 ( 1 − ϵ ) / 4 .
If G is a Ramanujan graph of sufficiently high degree, for any α < 1 , the decoding algorithm can correct ( α δ o 2 4 ) ( 1 − ∈ ) N errors, in O ( log n ) rounds ( where the big- O notation hides a dependence on α ). This can be implemented in linear time on a single processor; on n processors each round can be implemented in constant time.
Since the decoding algorithm is insensitive to the value of the edges and by linearity, we can assume that the transmitted codeword is the all zeros - vector. Let the received codeword be w . The set of edges which has an incorrect value while decoding is considered. Here by incorrect value, we mean 1 in any of the bits. Let w = w 0 be the initial value of the codeword, w 1 , w 2 , … , w t be the values after first, second . . . t stages of decoding. Here, X i = e ∈ E | x e i = 1 , and S i = v ∈ V i | E v ∩ X i + 1 ! = ∅ . Here S i corresponds to those set of vertices that was not able to successfully decode their codeword in the i t h round. From the above algorithm S 1 < S 0 as number of unsuccessful vertices will be corrected in every iteration. We can prove that S 0 > S 1 > S 2 > ⋯ is a decreasing sequence. In fact, | S i + 1 | <= ( 1 2 − α ) | S i | . As we are assuming, α < 1 , the above equation is in a geometric decreasing sequence. So, when | S i | < n , more than l o g 2 − α n rounds are necessary. Furthermore, ∑ | S i | = n ∑ ( 1 ( 2 − α ) i ) = O ( n ) , and if we implement the i t h round in O ( | S i | ) time, then the total sequential running time will be linear.
- It is lengthy process as the number of iterations m in decoder algorithm takes is [ ( log n ) / ( log ( 2 − α ) ) ]
- Zemor's decoding algorithm finds it difficult to decode erasures. A detailed way of how we can improve the algorithm is
given in.