.jpg)
Object Oriented Programming

Object-oriented programming (OOP) is a programming paradigm that represents the concept of "objects" that have data fields (attributes that describe the object) and associated procedures known as methods. Objects, which are usually instances of classes, are used to interact with one another to design applications and computer programs. C++, Objective-C, Smalltalk, Java, C#, Perl, Python, Ruby and PHP are examples of object-oriented programming languages.
The goals of object-oriented programming are:
Increased understanding.
Ease of maintenance.
Ease of evolution.
Terminology invoking "objects" and "oriented" in the modern sense of object-oriented programming made its first appearance at MIT in the late 1950s and early 1960s. In the environment of the artificial intelligence group, as early as 1960, "object" could refer to identified items (LISP atoms) with properties (attributes); Alan Kay was later to cite a detailed understanding of LISP internals as a strong influence on his thinking in 1966. Another early MIT example was Sketchpad created by Ivan Sutherland in 1960–61; in the glossary of the 1963 technical report based on his dissertation about Sketchpad, Sutherland defined notions of "object" and "instance" (with the class concept covered by "master" or "definition"), albeit specialized to graphical interaction. Also, an MIT ALGOL version, AED-0, linked data structures ("plexes", in that dialect) directly with procedures, prefiguring what were later termed "messages", "methods" and "member functions".
check out following link
4 major principles that make a language object-oriented: Encapsulation, Data Abstraction, Polymorphism and Inheritence.
Encapsulation
Well, in a nutshell, encapsulation is the hiding of data implementation by restricting access to accessors and mutators. First, lets define accessors and mutators:
Accessor
An accessor is a method that is used to ask an object about itself. In OOP, these are usually in the form of properties, which have, under
normal conditions, a get method, which is an accessor method. However, accessor methods are not restricted to properties and can be
any public method that gives information about the state of the object.
Mutator
Mutators are public methods that are used to modify the state of an object, while hiding the implementation of exactly how
the data gets modified. Mutators are commonly another portion of the property discussed above, except this time its the set method that lets the caller modify the member data behind the scenes.
Abstraction
Data abstraction is the simplest of principles to understand. Data abstraction and encapuslation are closely tied together, because a simple definition of data abstraction is the development of classes, objects, types in terms of their interfaces and functionality, instead of their implementation details. Abstraction denotes a model, a view, or some other focused representation for an actual item. Its the development of a software object to represent an object we can find in the real world. Encapsulation hides the details of that implementation.
Abstraction
is used to manage complexity. Software developers use abstraction todecompose complex systems into smaller components. As development progresss, programmers know the functionality they can expect from asyet undeveloped subsystems. Thus, programmers are not burdened by considering the waysin which the implementation of later subsystesm will affect the design of earlier development.
The best definition of abstraction I’ve ever read is: “An abstraction denotes the essential characteristics of an object that distinguish it from all other kinds of object and thus provide crisply defined conceptual boundaries, relative to the perspective of the viewer.” — G. Booch, Object-Oriented Design With Applications, Benjamin/Cummings, Menlo Park, California, 1991.
Lets look at this code for a person object. What are some things that a person can do? Those things must be represented here in our software model of a person. Things such as how tall the person is, and the age of the person; we need to be able to see those. We need the ability for the person to do things, such as run. We need to be able to ask the person if they can read.
So, in short, data abstraction is nothing more than the implementation of an object that contains the same essential properties and actions we can find in the original object we are representing.
Inheritance
Now lets discuss inheritance. Objects can relate to eachotherwith either a “has a”, “uses a” or an “is a” relationship. “Is a” is the inheritance way of object relationship. The example of this that has always stuck with me over the years is a library (I think I may have read it in something Grady Booch wrote). So, take a library, for example. A library lends more than just books, it also lends magazines, audiocassettes and microfilm. On somelevel, all of these items can be treated the same: All four types represent assets of the library that can be loaned out to people. However, even though the 4 types can be viewed as the same, they are not identical. A book has an ISBN and a magazine does not. And audiocassette has a play length and microfilm cannot be checked outovernight.
Each of these library’s assets should be represented by its own class definition. Without inheritance though, each class must independently implement the characteristics that are common to all loanable assets. All assets are either checked out or available
for checkout. All assets have a title, a date of acquisition and a replacement cost. Rather than duplicate functionality, inheritance allows you to inherit functionality from another class, called a superclass or base class.
Polymorphism
Polymorphism means one name, many forms. Polymorphism manifests itself by having multiple methods all with the same name, but slighty different functionality. Many VB6ers are familiar with interface polymorphism. I’m only going to discuss polymorphism from the point of view of inheritance because this is the part that is new to many people. Because of this, it can be difficult to fully grasp the full potential of polymorphism until you get some practice with it and see exactly what happens under different scenarios. We’re only going to talk about polymorphism, like the other topics, at the basic level.
There are 2 basic types of polymorphism. Overridding, also called run-time polymorphism, and overloading, which is referred to as compile-time polymorphism. This difference is, for method overloading, the compiler determines which method will be executed, and this decision is made when the code gets compiled. Which method will be used for method overriding is determined at runtime based on the dynamic type of an object.
Procedure Oriented Programming (POP) verses Object Oriented Programming (OOP)
Procedure Oriented Programming (POP)
Conventional programming using high level languages such as COBOL,FORTRAN and C, is commonly known as procedure oriented programming(POP). In the procedure oriented approach, the problem is viewed as a sequence of things to be done such as reading, calculating and printing. A number of functions are written to accomplish these tasks. The primary focus is on functions.
Procedure oriented programming basically consists of writing a list of instructions(or actions) for the computer to follow, and organizing these instructions into groups known as functions.While we concentrate on the development , very little attention is given to the data that are bing used by various functions.
In a multi-function program, many important data items are placed as global so that they may be accessed by all functions. Each function may have its own local data. Global data are more vulnerable to an inadvertent change by a function. In a large program it is very difficult to identify what data is used by which function. In case we need to revise an external data structure, we also need to revise all functions that access the data. This provides an opportunity for bugs to creep in.
Another serious drawback with the procedural approach is that it does not model real world problems very well. This is because functions are action-oriented and do not really correspond to the elements of the problem.
Some characteristics of Procedure Oriented Programming are :-
1) Emphasis is on doing things(algorithms).
2) Large programs are divided into smaller programs known as functions.
3) Most of the functions share global data.
4) Data more openly around the system from function to function.
5) Functions transform data from one form to another.
6) Employs top-down approach in program design.
Object Oriented Programming (OOP)
The major motivating factor in the invention of object oriented is to remove some of the flaws encountered in the procedural oriented approach. Object oriented programming treats data as a critical element in the program development and does not allow it to flow freely around the system. It ties data more closely to the functions that operate on it, and protects it from accidental modifications from outside functions.
Object oriented programming allows a decomposition of a problem into a number entities called objects and then builds data and functions around these objects. The data of an object can be accessed only by the functions associated with that object. However, functions of one object can access the functions of other objects.
The object oriented programming can be defined as an " approach that provides a way of modularizing programs by creating partitioned memory area for both data and functions that can be used as templates for creating copies of such modules on demand ". Thus, an object is considered to be a partitioned area of computer memory that stores data and set of operations that can access that data. Since the memory partitions are independent, the objects can be used in a variety of different programs without modifications.
Some characteristics of Object Oriented Programming are :-
1) Emphasis is on data rather than procedures or algorithms.
2) Programs are divided into what are known as objects.
3) Data structures are designed such that characterize the objects.
4) Functions that operate on the data are tied together in the data structure.
5) Data is hidden and cannot be accessed by external functions.
6) Objects may communicate with each other through functions.
7) New data and functions can be easily added whenever necessary.
8) Follows bottom-up approach in program design.
Benefits of Object Oriented Programming over Procedure Oriented Programming
1) Through inheritance, we can eliminate redundant code and extend the use of existing classes which is not possible in procedure oriented approach.
2) We can build programs from the standard working modules that communicate with one another, rather than having to start writing the code from scratch which happens procedure oriented approach. This leads to saving of development time and higher productivity.
3) The principle of data hiding helps the programmer to build secure programs that cannot be invaded by code in other parts of the program.
4) It is possible to have multiple instances of object to co-exist without any interference.
5) It is possible to map objects in the problem domain to those in the program.
6) It is easy to partition the work in a project based on objects .
6) The data-centered design approach enables us to capture more details of a model in implementable from.
7) Object oriented systems can be easily upgraded from small to large systems.
8) Message passing techniques for communication between objects makes the interface descriptions with external systems much simpler.
9) Software complexity can be easily managed.
more knowledge
what is C++ ?
check out following video for more knowledge
C++ (pronounced cee plus plus) is a general purpose programming language. It has imperative, object-oriented and generic programming features, while also providing the facilities for low level memory manipulation.
C++ is an object oriented programming (OOP) language, developed by Bjarne Stroustrup, and is an extension of C language. It is therefore possible to code C++ in a "C style" or "object-oriented style." In certain scenarios, it can be coded in either way and is thus an effective example of a hybrid language.
C++ is a general purpose object oriented programming language. It is considered to be an intermediate level language, as it encapsulates both high and low level language features. Initially, the language was called C with classes’ as it had all properties of C language with an additional concept of classes’. However, it was renamed to C++ in 1983. It is pronounced "C-Plus-Plus."
Techopedia explains C++ Programming Language
C++ is one of the most popular languages primarily utilized with system/application software, drivers, client-server applications and embedded firmware.
The main highlight of C++ is a collection of pre-defined classes, which are data types that can be instantiated multiple times. The language also facilitates declaration of user defined classes. Classes can further accommodate member functions to implement specific functionality. Multiple objects of a particular class can be defined to implement the functions within the class. Objects can be defined as instances created at run time. These classes can also be inherited by other new classes which take in the public and protected functionalities by default.
C++ includes several operators such as comparison, arithmetic, bit manipulation, logical operators etc. One of the most attractive features of C++ is that it enables the overloading of certain operators such as addition.
A few of the essential concepts within C++ programming language include polymorphism, virtual and friend functions, templates, namespaces and pointers.
Classes & Objects
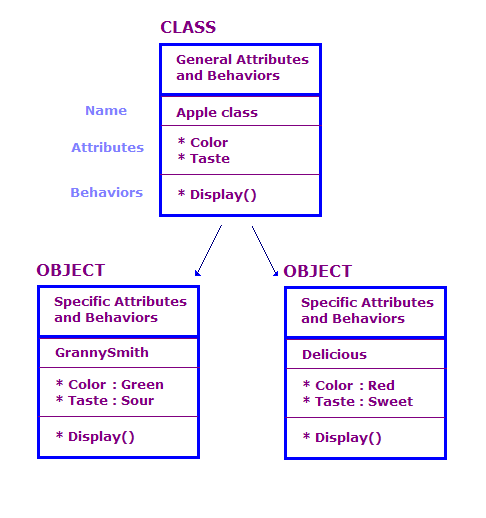
The main purpose of C++ programming is to add object orientation to the C programming language and classes are the central feature of C++ that supports object-oriented programming and are often called user-defined types.
A class is used to specify the form of an object and it combines data representation and methods for manipulating that data into one neat package. The data and functions within a class are called members of the class.
C++ Class Definitions
When you define a class, you define a blueprint for a data type. This doesnt actually define any data, but it does define what the class name means, that is, what an object of the class will consist of and what operations can be performed on such an object.
A class definition starts with the keyword class followed by the class name; and the class body, enclosed by a pair of curly braces. A class definition must be followed either by a semicolon or a list of declarations. For example, we defined the Box data type using the keyword class as follows:
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
The keyword public determines the access attributes of the members of the class that follow it. A public member can be accessed from outside the class anywhere within the scope of the class object. You can also specify the members of a class as private or protected which we will discuss in a sub-section.
Define C++ Objects
A class provides the blueprints for objects, so basically an object is created from a class. We declare objects of a class with exactly the same sort of declaration that we declare variables of basic types. Following statements declare two objects of class Box:
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
Both of the objects Box1 and Box2 will have their own copy of data members.
Accessing the Data Members:
The public data members of objects of a class can be accessed using the direct member access operator (.). Let us try the following example to make the things clear:
#include <iostream>
using namespace std;
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
int main( )
{
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;
// box 2 specification
Box2.height = 10.0;
Box2.length = 12.0;
Box2.breadth = 13.0;
// volume of box 1
volume = Box1.height * Box1.length * Box1.breadth;
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.height * Box2.length * Box2.breadth;
cout << "Volume of Box2 : " << volume <<endl;
return 0;
}
When the above code is compiled and executed, it produces the following result:
Volume of Box1 : 210
Volume of Box2 : 1560
It is important to note that private and protected members can not be accessed directly using direct member access operator (.).
Constructors & Destructors

The process of creating and deleting objects in C++ is not a trivial task. Every time an instance of a class is created the constructor method is called. The constructor has the same name as the class and it doesnt return any type, while the destructors name its defined in the same way, but with a ~ in front:
class String
{
public:
String() //constructor with no arguments
:str(NULL),
size(0)
{
}
String(int size) //constructor with one argument
:str(NULL),
size(size)
{
str = new char[size];
}
~String() //destructor
{
delete [] str;
};
private:
char *str;
int size;
}
Even if a class is not equipped with a constructor, the compiler will generate code for one, called the implicit default constructor. This will typically call the default constructors for all class members, if the class is using virtual methods it is used to initialize the pointer to the virtual table, and, in class hierarchies, it calls the constructors of the base classes. Both constructors in the above example use initialization lists in order to initialize the members of the class.
The construction order of the members is the order in which they are defined, and for this reason the same order should be preserved in the initialization list to avoid confusion.
Constructors
Preparing an Object for Action
A constructor is responsible for preparing the object for action, and in particular establishing initial values for all its data, i.e. its data members. Although it plays a special role, the constructor is just another member function, and in particular can be passed information via its argument list that can be used to initialise it. The name of the constructor function is the name of the class; thats how C++ knows its a constructor.
In Objects & Classes we started to develop a Track class. Suppose we want to be able to create track objects specifying mass and energy, then the first thing to be done is to add the constructor to the class definition file (i.e. the header file):-
class Track {
Float_t fEnergy;
Float_t fMass;
Float_t fMomentum;
Track(Float_t mass, Float_t energy);
Float_t GetEnergy();
void SetEnergy( Float_t energy);
};
Note the function is called Track. The other odd thing is there is no return value, the user cannot directly call the constructor function. Having declared it, we can now add its definition to the implementation file:-
#include "Track.h"
Float_t Track::GetEnergy() {
return fEnergy;
}
void Track::SetEnergy( Float_t energy ) {
fEnergy = energy;
fMomentum = sqrt( fEnergy*fEnergy - fMass*fMass );
}
Track::Track(Float_t mass, Float_t energy) {
fMass = mass;
SetEnergy(energy);
}
Remember the Track:: stuck at the front of each function is just telling the compiler that this belongs to (or is in the scope of) Track. The constructor function starts with:-
fMass = mass;
so sets the tracks mass. The next line deserves a bit more attention:-
SetEnergy(energy);
SetEnergy is another of the particles member functions. So in effect the object is sending itself a message. People talking to themselves is generally regarded as a bad thing, but with objects is often a sign of good class design. In this simple case, having already solved the problem of keeping momentum, mass and energy self consistent, we reuse the solution. Its another part of the OO ethic: Only solve a problem once. As the above example shows, when making internal calls like this, the member functions just looks like a normal function. Only if one object wants to call one of its siblings does it have to designate the target object, thus requiring the full object.function syntax.
Calling Constructors
Having defined a constructor, we can now make track objects. The syntax that was illustrated in Objects & Classes:-
Track MyTrack;
Track *MyTrackPtr = new Track;
now becomes:-
Track MyTrack(.135, 1.0);
Track *MyTrackPtr = new Track(.135, 1.0);
Of course we cannot send a object its constructor message, so the argument list is either supplied behind the identifier or the class name. As has been mentioned before,
Member Initialisation
C++ tries to make the syntax of user defined data types (i.e. classes) identical to the built in types where possible. The first form above is allowed for built in types. For example, instead of writing:-
Int MyInt = 3;
we can write:-
Int MyInt(3);
so we can treat int as having a constructor that takes a single argument that is an int. Although this notation isnt normally used like that it is often used in constructors. We could write:-
Track::Track(Float_t mass, Float_t energy) {
fMass = mass;
SetEnergy(energy);
}
as:-
Track::Track(Float_t mass, Float_t energy): fMass(mass) {
SetEnergy(energy);
}
the assignment has become an initialisation. The colon after the argument list signals this construction. If more than one variable is initialised like this they must be separated by commas. Although the syntax is not exactly intuitive, it does allow the compiler to optimise the code.
The Default Constructor
C++ requires that all classes have a default constructor, that is to say a constructor that can be used without arguments. This is a requirement in case it has to create a temporary object as part of the evaluation of some expression. Remember classes are just an extension of the language, the compiler must have a default way of creating any data type, including user defined ones. If we dont provide a default the compiler will supply one. We could write our own that just creates a null track:-
Track::Track(): fMass(0.), fMomentum(0.), fEnergy(0.) {}
The empty argument list shows this to be the default constructor. All the data members are initialised to zero leaving nothing for the function to do. Odd though this is, it is not an uncommon to see constructors like this. We have glossed over one point. We now have two constructors. Why doesnt the compiler complain - it certainly would if it were FORTRAN. The answer is that, so long as the compiler can decide which to use, its happy. In the examples we have seen in our Track class, its quite easy to tell which is the right one, just by looking at the size argument list. This duplication is called Overloading and is the subject of a later OO concepts topic.
Destructors
Tidying Up
When an object is no longer needed it has to be deleted. Objects created within functions as local variables, i.e. using the form:-
Track MyTrack;
are deleted automatically, once control leaves the innermost compound statement ( i.e. the innermost {..}) that contains the statement. For objects created dynamically:-
Track *MyTrackPtr = new Track;
the object remains until explicitly deleted, although, in the above statement, the pointer MyTrack is a local and will get deleted automatically. To delete a single object the delete operator is applied to a pointer to it:-
delete MyTrack;
To delete an array:-
delete [] MyTracks;
note that the array [] really is empty - the compiler takes care to record the array size.
Whenever an object is deleted its destructor member function is called. Its understandable why constructors are so important, objects must be properly initialised before they can be used, but is it really necessary to have a special member function that gets called when the object is about to disappear? In many cases, including our Track class as developed so far, the answer is no, we could leave the compiler to invent a default no-op one. However suppose our Track object contained a list of detector hits from which it was built. Without going into detail, its likely that this would be some kind of dynamic object owned by the Tack object and accessed via a pointer. Now when it comes time to delete the Track object, we want this list to be deleted, but probably not the hits that it points to! The compiler cannot possibly know, when it comes across a pointer in an object whether it points to something owned by the object and to be deleted as well, or simply something related to, but independent of, the object. So the rule is If an object, during its lifetime, creates other dynamic objects, it must have a destructor that deletes them afterwards. Failure to tidy up like this can leave to orphan objects that just clog up the memory, something that is called a memory leak. Even when a default is acceptable, its a good idea to define a destructor, so we should add the following line to our class definition:-
~Track() {};
As with the constructor, the function does not return a value. The function is called the class name but with a leading ~, which is the C++ complement operator - a bleak reminder that this function is the complement of creation! Currently it does nothing, as shown by the empty {}.
Object Ownership
Object ownership, and knowing when to delete an object is one of the knotty problems in OO. In the FORTRAN memory manager ZEBRA, the rule is very clear, each bank has a single parent, deleting the parent deletes it as well. In OO, objects lead a far more independent life. Its perfectly normal for an object to survive after its "parent", i.e. creator, has died.
Inheritance
One of the most important concepts in object-oriented programming is that of inheritance. Inheritance allows us to define a class in terms of another class, which makes it easier to create and maintain an application. This also provides an opportunity to reuse the code functionality and fast implementation time.
When creating a class, instead of writing completely new data members and member functions, the programmer can designate that the new class should inherit the members of an existing class. This existing class is called the base class, and the new class is referred to as the derived class.
The idea of inheritance implements the is a relationship. For example, mammal IS-A animal, dog IS-A mammal hence dog IS-A animal as well and so on.
Base & Derived Classes
A class can be derived from more than one classes, which means it can inherit data and functions from multiple base classes. To define a derived class, we use a class derivation list to specify the base class(es). A class derivation list names one or more base classes and has the form:
class derived-class: access-specifier base-class
Where access-specifier is one of public, protected, or private, and base-class is the name of a previously defined class. If the access-specifier is not used, then it is private by default.
Consider a base class Shape and its derived class Rectangle as follows:
#include <iostream>
using namespace std;
// Base class
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// Derived class
class Rectangle: public Shape
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
return 0;
}
When the above code is compiled and executed, it produces the following result:
Total area: 35
Access Control and Inheritance:
A derived class can access all the non-private members of its base class. Thus base-class members that should not be accessible to the member functions of derived classes should be declared private in the base class.
We can summarize the different access types according to who can access them in the following way:
Access public protected private
Same class yes yes yes
Derived classes yes yes no
Outside classes yes no no
A derived class inherits all base class methods with the following exceptions:
1. Constructors, destructors and copy constructors of the base class.
2. Overloaded operators of the base class.
3. The friend functions of the base class.
Type of Inheritance:
When deriving a class from a base class, the base class may be inherited through public, protected or private inheritance. The type of inheritance is specified by the access-specifier as explained above.
We hardly use protected or private inheritance, but public inheritance is commonly used. While using different type of inheritance, following rules are applied:
Public Inheritance: When deriving a class from a public base class, public members of the base class become public members of the derived class and protected members of the base class become protected members of the derived class. A base classs private members are never accessible directly from a derived class, but can be accessed through calls to the public and protected members of the base class.
see this video for extra knowledge
Protected Inheritance: When deriving from a protected base class, public and protected members of the base class become protected members of the derived class.
Private Inheritance: When deriving from a private base class, public and protected members of the base class become private members of the derived class.
Multiple Inheritances:
A C++ class can inherit members from more than one class and here is the extended syntax:
class derived-class: access baseA, access baseB....
Where access is one of public, protected, or private and would be given for every base class and they will be separated by comma as shown above. Let us try the following example:
#include <iostream>
using namespace std;
// Base class Shape
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// Base class PaintCost
class PaintCost
{
public:
int getCost(int area)
{
return area * 70;
}
};
// Derived class
class Rectangle: public Shape, public PaintCost
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
// Print the total cost of painting
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}
When the above code is compiled and executed, it produces the following result:
Total area: 35
Total paint cost: $2450
for more knowledge see this site

variables have been explained as locations in the computers memory which can be accessed by their identifier (their name). This way, the program does not need to care about the physical address of the data in memory; it simply uses the identifier whenever it needs to refer to the variable.
For a C++ program, the memory of a computer is like a succession of memory cells, each one byte in size, and each with a unique address. These single-byte memory cells are ordered in a way that allows data representations larger than one byte to occupy memory cells that have consecutive addresses.
This way, each cell can be easily located in the memory by means of its unique address. For example, the memory cell with the address 1776 always follows immediately after the cell with address 1775 and precedes the one with 1777, and is exactly one thousand cells after 776 and exactly one thousand cells before 2776.
When a variable is declared, the memory needed to store its value is assigned a specific location in memory (its memory address). Generally, C++ programs do not actively decide the exact memory addresses where its variables are stored. Fortunately, that task is left to the environment where the program is run - generally, an operating system that decides the particular memory locations on runtime. However, it may be useful for a program to be able to obtain the address of a variable during runtime in order to access data cells that are at a certain position relative to it.
Reference operator (&)
The address of a variable can be obtained by preceding the name of a variable with an ampersand sign (&), known as reference operator, and which can be literally translated as "address of". For example:
foo = &myvar;
This would assign the address of variable myvar to foo; by preceding the name of the variable myvar with the reference operator (&), we are no longer assigning the content of the variable itself to foo, but its address.
The actual address of a variable in memory cannot be known before runtime, but lets assume, in order to help clarify some concepts, that myvar is placed during runtime in the memory address 1776.
In this case, consider the following code fragment:
myvar = 25;
foo = &myvar;
bar = myvar;
The values contained in each variable after the execution of this are shown in the following diagram:
First, we have assigned the value 25 to myvar (a variable whose address in memory we assumed to be 1776).
The second statement assigns foo the address of myvar, which we have assumed to be 1776.
Finally, the third statement, assigns the value contained in myvar to bar. This is a standard assignment operation, as already done many times in earlier chapters.
The main difference between the second and third statements is the appearance of the reference operator (&).
The variable that stores the address of another variable (like foo in the previous example) is what in C++ is called a pointer. Pointers are a very powerful feature of the language that has many uses in lower level programming. A bit later, we will see how to declare and use pointers.
Dereference operator (*)
As just seen, a variable which stores the address of another variable is called a pointer. Pointers are said to "point to" the variable whose address they store.
An interesting property of pointers is that they can be used to access the variable they point to directly. This is done by preceding the pointer name with the dereference operator (*). The operator itself can be read as "value pointed to by".
Therefore, following with the values of the previous example, the following statement:
baz = *foo;
This could be read as: "baz equal to value pointed to by foo", and the statement would actually assign the value 25 to baz, since foo is 1776, and the value pointed to by 1776 (following the example above) would be 25.
It is important to clearly differentiate that foo refers to the value 1776, while *foo (with an asterisk * preceding the identifier) refers to the value stored at address 1776, which in this case is 25. Notice the difference of including or not including the dereference operator (I have added an explanatory comment of how each of these two expressions could be read):
baz = foo; // baz equal to foo (1776)
baz = *foo; // baz equal to value pointed to by foo (25)
The reference and dereference operators are thus complementary:
& is the reference operator, and can be read as "address of"
* is the dereference operator, and can be read as "value pointed to by"
Thus, they have sort of opposite meanings: A variable referenced with & can be dereferenced with *.
Earlier, we performed the following two assignment operations:
myvar = 25;
foo = &myvar;
Right after these two statements, all of the following expressions would give true as result:
myvar == 25
&myvar == 1776
foo == 1776
*foo == 25
The first expression is quite clear, considering that the assignment operation performed on myvar was myvar=25. The second one uses the reference operator (&), which returns the address of myvar, which we assumed it to have a value of 1776. The third one is somewhat obvious, since the second expression was true and the assignment operation performed on foo was foo=&myvar. The fourth expression uses the dereference operator (*) that can be read as "value pointed to by", and the value pointed to by foo is indeed 25.
So, after all that, you may also infer that for as long as the address pointed by foo remains unchanged, the following expression will also be true:
*foo == myvar
Declaring pointers
Due to the ability of a pointer to directly refer to the value that it points to, a pointer has different properties when it points to a char than when it points to an int or a float. Once dereferenced, the type needs to be known. And for that, the declaration of a pointer needs to include the data type the pointer is going to point to.
The declaration of pointers follows this syntax:
type * name;
where type is the data type pointed to by the pointer. This type is not the type of the pointer itself, but the type of the data the pointer points to. For example:
int * number;
char * character;
double * decimals;
These are three declarations of pointers. Each one is intended to point to a different data type, but, in fact, all of them are pointers and all of them are likely going to occupy the same amount of space in memory (the size in memory of a pointer depends on the platform where the program runs). Nevertheless, the data to which they point to do not occupy the same amount of space nor are of the same type: the first one points to an int, the second one to a char, and the last one to a double. Therefore, although these three example variables are all of them pointers, they actually have different types: int*, char*, and double* respectively, depending on the type they point to.
Note that the asterisk (*) used when declaring a pointer only means that it is a pointer (it is part of its type compound specifier), and should not be confused with the dereference operator seen a bit earlier, but which is also written with an asterisk (*). They are simply two different things represented with the same sign.
Polymorphism
The word polymorphism means having many forms. Typically, polymorphism occurs when there is a hierarchy of classes and they are related by inheritance.
C++ polymorphism means that a call to a member function will cause a different function to be executed depending on the type of object that invokes the function.
see this video for polymorphism concept
Consider the following example where a base class has been derived by other two classes:
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape{
public:
Rectangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape{
public:
Triangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// Main function for the program
int main( )
{
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// store the address of Rectangle
shape = &rec;
// call rectangle area.
shape->area();
// store the address of Triangle
shape = &tri;
// call triangle area.
shape->area();
return 0;
}
When the above code is compiled and executed, it produces the following result:
Parent class area
Parent class area
The reason for the incorrect output is that the call of the function area() is being set once by the compiler as the version defined in the base class. This is called static resolution of the function call, or static linkage - the function call is fixed before the program is executed. This is also sometimes called early binding because the area() function is set during the compilation of the program.
But now, lets make a slight modification in our program and precede the declaration of area() in the Shape class with the keyword virtual so that it looks like this:
class Shape
{
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
After this slight modification, when the previous example code is compiled and executed, it produces the following result:
Rectangle class area
Triangle class area
This time, the compiler looks at the contents of the pointer instead of its type. Hence, since addresses of objects of tri and rec classes are stored in *shape the respective area() function is called.
As you can see, each of the child classes has a separate implementation for the function area(). This is how polymorphism is generally used. You have different classes with a function of the same name, and even the same parameters, but with different implementations.
Virtual Function:
A virtual function is a function in a base class that is declared using the keyword virtual. Defining in a base class a virtual function, with another version in a derived class, signals to the compiler that we dont want static linkage for this function.
What we do want is the selection of the function to be called at any given point in the program to be based on the kind of object for which it is called. This sort of operation is referred to as dynamic linkage, or late binding.
Pure Virtual Functions:
Its possible that youd want to include a virtual function in a base class so that it may be redefined in a derived class to suit the objects of that class, but that there is no meaningful definition you could give for the function in the base class.
We can change the virtual function area() in the base class to the following:
class Shape
{
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};
The = 0 tells the compiler that the function has no body and above virtual function will be called pure virtual function.
Object-oriented programming (OOP) is a programming paradigm that represents the concept of "objects" that have data fields (attributes that describe the object) and associated procedures known as methods. Objects, which are usually instances of classes, are used to interact with one another to design applications and computer programs. C++, Objective-C, Smalltalk, Java, C#, Perl, Python, Ruby and PHP are examples of object-oriented programming languages.
The goals of object-oriented programming are:
Increased understanding.
Ease of maintenance.
Ease of evolution.
Terminology invoking "objects" and "oriented" in the modern sense of object-oriented programming made its first appearance at MIT in the late 1950s and early 1960s. In the environment of the artificial intelligence group, as early as 1960, "object" could refer to identified items (LISP atoms) with properties (attributes); Alan Kay was later to cite a detailed understanding of LISP internals as a strong influence on his thinking in 1966. Another early MIT example was Sketchpad created by Ivan Sutherland in 1960–61; in the glossary of the 1963 technical report based on his dissertation about Sketchpad, Sutherland defined notions of "object" and "instance" (with the class concept covered by "master" or "definition"), albeit specialized to graphical interaction. Also, an MIT ALGOL version, AED-0, linked data structures ("plexes", in that dialect) directly with procedures, prefiguring what were later termed "messages", "methods" and "member functions".
check out following link
http://www.tutorialspoint.com/cplusplus/index.htm
principles of Object-Oriented ProgrammingC++ Tutorial
C++ Tutorial for Beginners - Learning C++ in simple and easy steps : A beginners tutorial containing complete knowledge of C++ Syntax Object Oriented Language, Methods, Overriding, Inheritance, Polymorphism, Interfaces, STL, Iterators, Algorithms, Exception Handling, Overloading,Templates, Namespaces and Signal Handling
4 major principles that make a language object-oriented: Encapsulation, Data Abstraction, Polymorphism and Inheritence.
Encapsulation
Well, in a nutshell, encapsulation is the hiding of data implementation by restricting access to accessors and mutators. First, lets define accessors and mutators:
Accessor
An accessor is a method that is used to ask an object about itself. In OOP, these are usually in the form of properties, which have, under
normal conditions, a get method, which is an accessor method. However, accessor methods are not restricted to properties and can be
any public method that gives information about the state of the object.
Mutator
Mutators are public methods that are used to modify the state of an object, while hiding the implementation of exactly how
the data gets modified. Mutators are commonly another portion of the property discussed above, except this time its the set method that lets the caller modify the member data behind the scenes.
Abstraction
Data abstraction is the simplest of principles to understand. Data abstraction and encapuslation are closely tied together, because a simple definition of data abstraction is the development of classes, objects, types in terms of their interfaces and functionality, instead of their implementation details. Abstraction denotes a model, a view, or some other focused representation for an actual item. Its the development of a software object to represent an object we can find in the real world. Encapsulation hides the details of that implementation.
Abstraction
is used to manage complexity. Software developers use abstraction todecompose complex systems into smaller components. As development progresss, programmers know the functionality they can expect from asyet undeveloped subsystems. Thus, programmers are not burdened by considering the waysin which the implementation of later subsystesm will affect the design of earlier development.
The best definition of abstraction I’ve ever read is: “An abstraction denotes the essential characteristics of an object that distinguish it from all other kinds of object and thus provide crisply defined conceptual boundaries, relative to the perspective of the viewer.” — G. Booch, Object-Oriented Design With Applications, Benjamin/Cummings, Menlo Park, California, 1991.
Lets look at this code for a person object. What are some things that a person can do? Those things must be represented here in our software model of a person. Things such as how tall the person is, and the age of the person; we need to be able to see those. We need the ability for the person to do things, such as run. We need to be able to ask the person if they can read.
So, in short, data abstraction is nothing more than the implementation of an object that contains the same essential properties and actions we can find in the original object we are representing.
Inheritance
Now lets discuss inheritance. Objects can relate to eachotherwith either a “has a”, “uses a” or an “is a” relationship. “Is a” is the inheritance way of object relationship. The example of this that has always stuck with me over the years is a library (I think I may have read it in something Grady Booch wrote). So, take a library, for example. A library lends more than just books, it also lends magazines, audiocassettes and microfilm. On somelevel, all of these items can be treated the same: All four types represent assets of the library that can be loaned out to people. However, even though the 4 types can be viewed as the same, they are not identical. A book has an ISBN and a magazine does not. And audiocassette has a play length and microfilm cannot be checked outovernight.
Each of these library’s assets should be represented by its own class definition. Without inheritance though, each class must independently implement the characteristics that are common to all loanable assets. All assets are either checked out or available
for checkout. All assets have a title, a date of acquisition and a replacement cost. Rather than duplicate functionality, inheritance allows you to inherit functionality from another class, called a superclass or base class.
Polymorphism
Polymorphism means one name, many forms. Polymorphism manifests itself by having multiple methods all with the same name, but slighty different functionality. Many VB6ers are familiar with interface polymorphism. I’m only going to discuss polymorphism from the point of view of inheritance because this is the part that is new to many people. Because of this, it can be difficult to fully grasp the full potential of polymorphism until you get some practice with it and see exactly what happens under different scenarios. We’re only going to talk about polymorphism, like the other topics, at the basic level.
There are 2 basic types of polymorphism. Overridding, also called run-time polymorphism, and overloading, which is referred to as compile-time polymorphism. This difference is, for method overloading, the compiler determines which method will be executed, and this decision is made when the code gets compiled. Which method will be used for method overriding is determined at runtime based on the dynamic type of an object.
Procedure Oriented Programming (POP) verses Object Oriented Programming (OOP)
Procedure Oriented Programming (POP)
Conventional programming using high level languages such as COBOL,FORTRAN and C, is commonly known as procedure oriented programming(POP). In the procedure oriented approach, the problem is viewed as a sequence of things to be done such as reading, calculating and printing. A number of functions are written to accomplish these tasks. The primary focus is on functions.
Procedure oriented programming basically consists of writing a list of instructions(or actions) for the computer to follow, and organizing these instructions into groups known as functions.While we concentrate on the development , very little attention is given to the data that are bing used by various functions.
In a multi-function program, many important data items are placed as global so that they may be accessed by all functions. Each function may have its own local data. Global data are more vulnerable to an inadvertent change by a function. In a large program it is very difficult to identify what data is used by which function. In case we need to revise an external data structure, we also need to revise all functions that access the data. This provides an opportunity for bugs to creep in.
Another serious drawback with the procedural approach is that it does not model real world problems very well. This is because functions are action-oriented and do not really correspond to the elements of the problem.
Some characteristics of Procedure Oriented Programming are :-
1) Emphasis is on doing things(algorithms).
2) Large programs are divided into smaller programs known as functions.
3) Most of the functions share global data.
4) Data more openly around the system from function to function.
5) Functions transform data from one form to another.
6) Employs top-down approach in program design.
Object Oriented Programming (OOP)
The major motivating factor in the invention of object oriented is to remove some of the flaws encountered in the procedural oriented approach. Object oriented programming treats data as a critical element in the program development and does not allow it to flow freely around the system. It ties data more closely to the functions that operate on it, and protects it from accidental modifications from outside functions.
Object oriented programming allows a decomposition of a problem into a number entities called objects and then builds data and functions around these objects. The data of an object can be accessed only by the functions associated with that object. However, functions of one object can access the functions of other objects.
The object oriented programming can be defined as an " approach that provides a way of modularizing programs by creating partitioned memory area for both data and functions that can be used as templates for creating copies of such modules on demand ". Thus, an object is considered to be a partitioned area of computer memory that stores data and set of operations that can access that data. Since the memory partitions are independent, the objects can be used in a variety of different programs without modifications.
Some characteristics of Object Oriented Programming are :-
1) Emphasis is on data rather than procedures or algorithms.
2) Programs are divided into what are known as objects.
3) Data structures are designed such that characterize the objects.
4) Functions that operate on the data are tied together in the data structure.
5) Data is hidden and cannot be accessed by external functions.
6) Objects may communicate with each other through functions.
7) New data and functions can be easily added whenever necessary.
8) Follows bottom-up approach in program design.
Benefits of Object Oriented Programming over Procedure Oriented Programming
1) Through inheritance, we can eliminate redundant code and extend the use of existing classes which is not possible in procedure oriented approach.
2) We can build programs from the standard working modules that communicate with one another, rather than having to start writing the code from scratch which happens procedure oriented approach. This leads to saving of development time and higher productivity.
3) The principle of data hiding helps the programmer to build secure programs that cannot be invaded by code in other parts of the program.
4) It is possible to have multiple instances of object to co-exist without any interference.
5) It is possible to map objects in the problem domain to those in the program.
6) It is easy to partition the work in a project based on objects .
6) The data-centered design approach enables us to capture more details of a model in implementable from.
7) Object oriented systems can be easily upgraded from small to large systems.
8) Message passing techniques for communication between objects makes the interface descriptions with external systems much simpler.
9) Software complexity can be easily managed.
more knowledge
what is C++ ?
check out following video for more knowledge
C++ (pronounced cee plus plus) is a general purpose programming language. It has imperative, object-oriented and generic programming features, while also providing the facilities for low level memory manipulation.
C++ is an object oriented programming (OOP) language, developed by Bjarne Stroustrup, and is an extension of C language. It is therefore possible to code C++ in a "C style" or "object-oriented style." In certain scenarios, it can be coded in either way and is thus an effective example of a hybrid language.
C++ is a general purpose object oriented programming language. It is considered to be an intermediate level language, as it encapsulates both high and low level language features. Initially, the language was called C with classes’ as it had all properties of C language with an additional concept of classes’. However, it was renamed to C++ in 1983. It is pronounced "C-Plus-Plus."
Techopedia explains C++ Programming Language
C++ is one of the most popular languages primarily utilized with system/application software, drivers, client-server applications and embedded firmware.
The main highlight of C++ is a collection of pre-defined classes, which are data types that can be instantiated multiple times. The language also facilitates declaration of user defined classes. Classes can further accommodate member functions to implement specific functionality. Multiple objects of a particular class can be defined to implement the functions within the class. Objects can be defined as instances created at run time. These classes can also be inherited by other new classes which take in the public and protected functionalities by default.
C++ includes several operators such as comparison, arithmetic, bit manipulation, logical operators etc. One of the most attractive features of C++ is that it enables the overloading of certain operators such as addition.
A few of the essential concepts within C++ programming language include polymorphism, virtual and friend functions, templates, namespaces and pointers.
Classes & Objects
The main purpose of C++ programming is to add object orientation to the C programming language and classes are the central feature of C++ that supports object-oriented programming and are often called user-defined types.
A class is used to specify the form of an object and it combines data representation and methods for manipulating that data into one neat package. The data and functions within a class are called members of the class.
C++ Class Definitions
When you define a class, you define a blueprint for a data type. This doesnt actually define any data, but it does define what the class name means, that is, what an object of the class will consist of and what operations can be performed on such an object.
A class definition starts with the keyword class followed by the class name; and the class body, enclosed by a pair of curly braces. A class definition must be followed either by a semicolon or a list of declarations. For example, we defined the Box data type using the keyword class as follows:
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
The keyword public determines the access attributes of the members of the class that follow it. A public member can be accessed from outside the class anywhere within the scope of the class object. You can also specify the members of a class as private or protected which we will discuss in a sub-section.
Define C++ Objects
A class provides the blueprints for objects, so basically an object is created from a class. We declare objects of a class with exactly the same sort of declaration that we declare variables of basic types. Following statements declare two objects of class Box:
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
Both of the objects Box1 and Box2 will have their own copy of data members.
Accessing the Data Members:
The public data members of objects of a class can be accessed using the direct member access operator (.). Let us try the following example to make the things clear:
#include <iostream>
using namespace std;
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
int main( )
{
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
Box1.height = 5.0;
Box1.length = 6.0;
Box1.breadth = 7.0;
// box 2 specification
Box2.height = 10.0;
Box2.length = 12.0;
Box2.breadth = 13.0;
// volume of box 1
volume = Box1.height * Box1.length * Box1.breadth;
cout << "Volume of Box1 : " << volume <<endl;
// volume of box 2
volume = Box2.height * Box2.length * Box2.breadth;
cout << "Volume of Box2 : " << volume <<endl;
return 0;
}
When the above code is compiled and executed, it produces the following result:
Volume of Box1 : 210
Volume of Box2 : 1560
It is important to note that private and protected members can not be accessed directly using direct member access operator (.).
Constructors & Destructors
The process of creating and deleting objects in C++ is not a trivial task. Every time an instance of a class is created the constructor method is called. The constructor has the same name as the class and it doesnt return any type, while the destructors name its defined in the same way, but with a ~ in front:
class String
{
public:
String() //constructor with no arguments
:str(NULL),
size(0)
{
}
String(int size) //constructor with one argument
:str(NULL),
size(size)
{
str = new char[size];
}
~String() //destructor
{
delete [] str;
};
private:
char *str;
int size;
}
Even if a class is not equipped with a constructor, the compiler will generate code for one, called the implicit default constructor. This will typically call the default constructors for all class members, if the class is using virtual methods it is used to initialize the pointer to the virtual table, and, in class hierarchies, it calls the constructors of the base classes. Both constructors in the above example use initialization lists in order to initialize the members of the class.
The construction order of the members is the order in which they are defined, and for this reason the same order should be preserved in the initialization list to avoid confusion.
Constructors
Preparing an Object for Action
A constructor is responsible for preparing the object for action, and in particular establishing initial values for all its data, i.e. its data members. Although it plays a special role, the constructor is just another member function, and in particular can be passed information via its argument list that can be used to initialise it. The name of the constructor function is the name of the class; thats how C++ knows its a constructor.
In Objects & Classes we started to develop a Track class. Suppose we want to be able to create track objects specifying mass and energy, then the first thing to be done is to add the constructor to the class definition file (i.e. the header file):-
class Track {
Float_t fEnergy;
Float_t fMass;
Float_t fMomentum;
Track(Float_t mass, Float_t energy);
Float_t GetEnergy();
void SetEnergy( Float_t energy);
};
Note the function is called Track. The other odd thing is there is no return value, the user cannot directly call the constructor function. Having declared it, we can now add its definition to the implementation file:-
#include "Track.h"
Float_t Track::GetEnergy() {
return fEnergy;
}
void Track::SetEnergy( Float_t energy ) {
fEnergy = energy;
fMomentum = sqrt( fEnergy*fEnergy - fMass*fMass );
}
Track::Track(Float_t mass, Float_t energy) {
fMass = mass;
SetEnergy(energy);
}
Remember the Track:: stuck at the front of each function is just telling the compiler that this belongs to (or is in the scope of) Track. The constructor function starts with:-
fMass = mass;
so sets the tracks mass. The next line deserves a bit more attention:-
SetEnergy(energy);
SetEnergy is another of the particles member functions. So in effect the object is sending itself a message. People talking to themselves is generally regarded as a bad thing, but with objects is often a sign of good class design. In this simple case, having already solved the problem of keeping momentum, mass and energy self consistent, we reuse the solution. Its another part of the OO ethic: Only solve a problem once. As the above example shows, when making internal calls like this, the member functions just looks like a normal function. Only if one object wants to call one of its siblings does it have to designate the target object, thus requiring the full object.function syntax.
Calling Constructors
Having defined a constructor, we can now make track objects. The syntax that was illustrated in Objects & Classes:-
Track MyTrack;
Track *MyTrackPtr = new Track;
now becomes:-
Track MyTrack(.135, 1.0);
Track *MyTrackPtr = new Track(.135, 1.0);
Of course we cannot send a object its constructor message, so the argument list is either supplied behind the identifier or the class name. As has been mentioned before,
Member Initialisation
C++ tries to make the syntax of user defined data types (i.e. classes) identical to the built in types where possible. The first form above is allowed for built in types. For example, instead of writing:-
Int MyInt = 3;
we can write:-
Int MyInt(3);
so we can treat int as having a constructor that takes a single argument that is an int. Although this notation isnt normally used like that it is often used in constructors. We could write:-
Track::Track(Float_t mass, Float_t energy) {
fMass = mass;
SetEnergy(energy);
}
as:-
Track::Track(Float_t mass, Float_t energy): fMass(mass) {
SetEnergy(energy);
}
the assignment has become an initialisation. The colon after the argument list signals this construction. If more than one variable is initialised like this they must be separated by commas. Although the syntax is not exactly intuitive, it does allow the compiler to optimise the code.
The Default Constructor
C++ requires that all classes have a default constructor, that is to say a constructor that can be used without arguments. This is a requirement in case it has to create a temporary object as part of the evaluation of some expression. Remember classes are just an extension of the language, the compiler must have a default way of creating any data type, including user defined ones. If we dont provide a default the compiler will supply one. We could write our own that just creates a null track:-
Track::Track(): fMass(0.), fMomentum(0.), fEnergy(0.) {}
The empty argument list shows this to be the default constructor. All the data members are initialised to zero leaving nothing for the function to do. Odd though this is, it is not an uncommon to see constructors like this. We have glossed over one point. We now have two constructors. Why doesnt the compiler complain - it certainly would if it were FORTRAN. The answer is that, so long as the compiler can decide which to use, its happy. In the examples we have seen in our Track class, its quite easy to tell which is the right one, just by looking at the size argument list. This duplication is called Overloading and is the subject of a later OO concepts topic.
Destructors
Tidying Up
When an object is no longer needed it has to be deleted. Objects created within functions as local variables, i.e. using the form:-
Track MyTrack;
are deleted automatically, once control leaves the innermost compound statement ( i.e. the innermost {..}) that contains the statement. For objects created dynamically:-
Track *MyTrackPtr = new Track;
the object remains until explicitly deleted, although, in the above statement, the pointer MyTrack is a local and will get deleted automatically. To delete a single object the delete operator is applied to a pointer to it:-
delete MyTrack;
To delete an array:-
delete [] MyTracks;
note that the array [] really is empty - the compiler takes care to record the array size.
Whenever an object is deleted its destructor member function is called. Its understandable why constructors are so important, objects must be properly initialised before they can be used, but is it really necessary to have a special member function that gets called when the object is about to disappear? In many cases, including our Track class as developed so far, the answer is no, we could leave the compiler to invent a default no-op one. However suppose our Track object contained a list of detector hits from which it was built. Without going into detail, its likely that this would be some kind of dynamic object owned by the Tack object and accessed via a pointer. Now when it comes time to delete the Track object, we want this list to be deleted, but probably not the hits that it points to! The compiler cannot possibly know, when it comes across a pointer in an object whether it points to something owned by the object and to be deleted as well, or simply something related to, but independent of, the object. So the rule is If an object, during its lifetime, creates other dynamic objects, it must have a destructor that deletes them afterwards. Failure to tidy up like this can leave to orphan objects that just clog up the memory, something that is called a memory leak. Even when a default is acceptable, its a good idea to define a destructor, so we should add the following line to our class definition:-
~Track() {};
As with the constructor, the function does not return a value. The function is called the class name but with a leading ~, which is the C++ complement operator - a bleak reminder that this function is the complement of creation! Currently it does nothing, as shown by the empty {}.
Object Ownership
Object ownership, and knowing when to delete an object is one of the knotty problems in OO. In the FORTRAN memory manager ZEBRA, the rule is very clear, each bank has a single parent, deleting the parent deletes it as well. In OO, objects lead a far more independent life. Its perfectly normal for an object to survive after its "parent", i.e. creator, has died.
Inheritance
One of the most important concepts in object-oriented programming is that of inheritance. Inheritance allows us to define a class in terms of another class, which makes it easier to create and maintain an application. This also provides an opportunity to reuse the code functionality and fast implementation time.
When creating a class, instead of writing completely new data members and member functions, the programmer can designate that the new class should inherit the members of an existing class. This existing class is called the base class, and the new class is referred to as the derived class.
The idea of inheritance implements the is a relationship. For example, mammal IS-A animal, dog IS-A mammal hence dog IS-A animal as well and so on.
Base & Derived Classes
A class can be derived from more than one classes, which means it can inherit data and functions from multiple base classes. To define a derived class, we use a class derivation list to specify the base class(es). A class derivation list names one or more base classes and has the form:
class derived-class: access-specifier base-class
Where access-specifier is one of public, protected, or private, and base-class is the name of a previously defined class. If the access-specifier is not used, then it is private by default.
Consider a base class Shape and its derived class Rectangle as follows:
#include <iostream>
using namespace std;
// Base class
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// Derived class
class Rectangle: public Shape
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
return 0;
}
When the above code is compiled and executed, it produces the following result:
Total area: 35
Access Control and Inheritance:
A derived class can access all the non-private members of its base class. Thus base-class members that should not be accessible to the member functions of derived classes should be declared private in the base class.
We can summarize the different access types according to who can access them in the following way:
Access public protected private
Same class yes yes yes
Derived classes yes yes no
Outside classes yes no no
A derived class inherits all base class methods with the following exceptions:
1. Constructors, destructors and copy constructors of the base class.
2. Overloaded operators of the base class.
3. The friend functions of the base class.
Type of Inheritance:
When deriving a class from a base class, the base class may be inherited through public, protected or private inheritance. The type of inheritance is specified by the access-specifier as explained above.
We hardly use protected or private inheritance, but public inheritance is commonly used. While using different type of inheritance, following rules are applied:
Public Inheritance: When deriving a class from a public base class, public members of the base class become public members of the derived class and protected members of the base class become protected members of the derived class. A base classs private members are never accessible directly from a derived class, but can be accessed through calls to the public and protected members of the base class.
see this video for extra knowledge
Protected Inheritance: When deriving from a protected base class, public and protected members of the base class become protected members of the derived class.
Private Inheritance: When deriving from a private base class, public and protected members of the base class become private members of the derived class.
Multiple Inheritances:
A C++ class can inherit members from more than one class and here is the extended syntax:
class derived-class: access baseA, access baseB....
Where access is one of public, protected, or private and would be given for every base class and they will be separated by comma as shown above. Let us try the following example:
#include <iostream>
using namespace std;
// Base class Shape
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
};
// Base class PaintCost
class PaintCost
{
public:
int getCost(int area)
{
return area * 70;
}
};
// Derived class
class Rectangle: public Shape, public PaintCost
{
public:
int getArea()
{
return (width * height);
}
};
int main(void)
{
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// Print the area of the object.
cout << "Total area: " << Rect.getArea() << endl;
// Print the total cost of painting
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}
When the above code is compiled and executed, it produces the following result:
Total area: 35
Total paint cost: $2450
for more knowledge see this site
http://www.introprogramming.info/english-intro-csharp-book/read-online/chapter-20-object-oriented-programming-principles/
Pointers in c++Introduction to Programming with C# / Java Books » Chapter 20. Object-Oriented Programming Principles (OOP)
Fundamentals of Computer Programming with C# by Svetlin Nakov & Co. - free e-book - official web site
variables have been explained as locations in the computers memory which can be accessed by their identifier (their name). This way, the program does not need to care about the physical address of the data in memory; it simply uses the identifier whenever it needs to refer to the variable.
For a C++ program, the memory of a computer is like a succession of memory cells, each one byte in size, and each with a unique address. These single-byte memory cells are ordered in a way that allows data representations larger than one byte to occupy memory cells that have consecutive addresses.
This way, each cell can be easily located in the memory by means of its unique address. For example, the memory cell with the address 1776 always follows immediately after the cell with address 1775 and precedes the one with 1777, and is exactly one thousand cells after 776 and exactly one thousand cells before 2776.
When a variable is declared, the memory needed to store its value is assigned a specific location in memory (its memory address). Generally, C++ programs do not actively decide the exact memory addresses where its variables are stored. Fortunately, that task is left to the environment where the program is run - generally, an operating system that decides the particular memory locations on runtime. However, it may be useful for a program to be able to obtain the address of a variable during runtime in order to access data cells that are at a certain position relative to it.
Reference operator (&)
The address of a variable can be obtained by preceding the name of a variable with an ampersand sign (&), known as reference operator, and which can be literally translated as "address of". For example:
foo = &myvar;
This would assign the address of variable myvar to foo; by preceding the name of the variable myvar with the reference operator (&), we are no longer assigning the content of the variable itself to foo, but its address.
The actual address of a variable in memory cannot be known before runtime, but lets assume, in order to help clarify some concepts, that myvar is placed during runtime in the memory address 1776.
In this case, consider the following code fragment:
myvar = 25;
foo = &myvar;
bar = myvar;
The values contained in each variable after the execution of this are shown in the following diagram:
First, we have assigned the value 25 to myvar (a variable whose address in memory we assumed to be 1776).
The second statement assigns foo the address of myvar, which we have assumed to be 1776.
Finally, the third statement, assigns the value contained in myvar to bar. This is a standard assignment operation, as already done many times in earlier chapters.
The main difference between the second and third statements is the appearance of the reference operator (&).
The variable that stores the address of another variable (like foo in the previous example) is what in C++ is called a pointer. Pointers are a very powerful feature of the language that has many uses in lower level programming. A bit later, we will see how to declare and use pointers.
Dereference operator (*)
As just seen, a variable which stores the address of another variable is called a pointer. Pointers are said to "point to" the variable whose address they store.
An interesting property of pointers is that they can be used to access the variable they point to directly. This is done by preceding the pointer name with the dereference operator (*). The operator itself can be read as "value pointed to by".
Therefore, following with the values of the previous example, the following statement:
baz = *foo;
This could be read as: "baz equal to value pointed to by foo", and the statement would actually assign the value 25 to baz, since foo is 1776, and the value pointed to by 1776 (following the example above) would be 25.
It is important to clearly differentiate that foo refers to the value 1776, while *foo (with an asterisk * preceding the identifier) refers to the value stored at address 1776, which in this case is 25. Notice the difference of including or not including the dereference operator (I have added an explanatory comment of how each of these two expressions could be read):
baz = foo; // baz equal to foo (1776)
baz = *foo; // baz equal to value pointed to by foo (25)
The reference and dereference operators are thus complementary:
& is the reference operator, and can be read as "address of"
* is the dereference operator, and can be read as "value pointed to by"
Thus, they have sort of opposite meanings: A variable referenced with & can be dereferenced with *.
Earlier, we performed the following two assignment operations:
myvar = 25;
foo = &myvar;
Right after these two statements, all of the following expressions would give true as result:
myvar == 25
&myvar == 1776
foo == 1776
*foo == 25
The first expression is quite clear, considering that the assignment operation performed on myvar was myvar=25. The second one uses the reference operator (&), which returns the address of myvar, which we assumed it to have a value of 1776. The third one is somewhat obvious, since the second expression was true and the assignment operation performed on foo was foo=&myvar. The fourth expression uses the dereference operator (*) that can be read as "value pointed to by", and the value pointed to by foo is indeed 25.
So, after all that, you may also infer that for as long as the address pointed by foo remains unchanged, the following expression will also be true:
*foo == myvar
Declaring pointers
Due to the ability of a pointer to directly refer to the value that it points to, a pointer has different properties when it points to a char than when it points to an int or a float. Once dereferenced, the type needs to be known. And for that, the declaration of a pointer needs to include the data type the pointer is going to point to.
The declaration of pointers follows this syntax:
type * name;
where type is the data type pointed to by the pointer. This type is not the type of the pointer itself, but the type of the data the pointer points to. For example:
int * number;
char * character;
double * decimals;
These are three declarations of pointers. Each one is intended to point to a different data type, but, in fact, all of them are pointers and all of them are likely going to occupy the same amount of space in memory (the size in memory of a pointer depends on the platform where the program runs). Nevertheless, the data to which they point to do not occupy the same amount of space nor are of the same type: the first one points to an int, the second one to a char, and the last one to a double. Therefore, although these three example variables are all of them pointers, they actually have different types: int*, char*, and double* respectively, depending on the type they point to.
Note that the asterisk (*) used when declaring a pointer only means that it is a pointer (it is part of its type compound specifier), and should not be confused with the dereference operator seen a bit earlier, but which is also written with an asterisk (*). They are simply two different things represented with the same sign.
Polymorphism
The word polymorphism means having many forms. Typically, polymorphism occurs when there is a hierarchy of classes and they are related by inheritance.
C++ polymorphism means that a call to a member function will cause a different function to be executed depending on the type of object that invokes the function.
see this video for polymorphism concept
Consider the following example where a base class has been derived by other two classes:
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
class Rectangle: public Shape{
public:
Rectangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Rectangle class area :" <<endl;
return (width * height);
}
};
class Triangle: public Shape{
public:
Triangle( int a=0, int b=0):Shape(a, b) { }
int area ()
{
cout << "Triangle class area :" <<endl;
return (width * height / 2);
}
};
// Main function for the program
int main( )
{
Shape *shape;
Rectangle rec(10,7);
Triangle tri(10,5);
// store the address of Rectangle
shape = &rec;
// call rectangle area.
shape->area();
// store the address of Triangle
shape = &tri;
// call triangle area.
shape->area();
return 0;
}
When the above code is compiled and executed, it produces the following result:
Parent class area
Parent class area
The reason for the incorrect output is that the call of the function area() is being set once by the compiler as the version defined in the base class. This is called static resolution of the function call, or static linkage - the function call is fixed before the program is executed. This is also sometimes called early binding because the area() function is set during the compilation of the program.
But now, lets make a slight modification in our program and precede the declaration of area() in the Shape class with the keyword virtual so that it looks like this:
class Shape
{
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
virtual int area()
{
cout << "Parent class area :" <<endl;
return 0;
}
};
After this slight modification, when the previous example code is compiled and executed, it produces the following result:
Rectangle class area
Triangle class area
This time, the compiler looks at the contents of the pointer instead of its type. Hence, since addresses of objects of tri and rec classes are stored in *shape the respective area() function is called.
As you can see, each of the child classes has a separate implementation for the function area(). This is how polymorphism is generally used. You have different classes with a function of the same name, and even the same parameters, but with different implementations.
Virtual Function:
A virtual function is a function in a base class that is declared using the keyword virtual. Defining in a base class a virtual function, with another version in a derived class, signals to the compiler that we dont want static linkage for this function.
What we do want is the selection of the function to be called at any given point in the program to be based on the kind of object for which it is called. This sort of operation is referred to as dynamic linkage, or late binding.
Pure Virtual Functions:
Its possible that youd want to include a virtual function in a base class so that it may be redefined in a derived class to suit the objects of that class, but that there is no meaningful definition you could give for the function in the base class.
We can change the virtual function area() in the base class to the following:
class Shape
{
protected:
int width, height;
public:
Shape( int a=0, int b=0)
{
width = a;
height = b;
}
// pure virtual function
virtual int area() = 0;
};
The = 0 tells the compiler that the function has no body and above virtual function will be called pure virtual function.