In data structures, a range query consists of preprocessing some input data into a data structure to efficiently answer any number of queries on any subset of the input. Particularly, there is a group of problems that have been extensively studied where the input is an array of unsorted numbers and a query consists of computing some function on a specific range of the array. In this article we describe some of these problems together with their solutions.
We may state the problem of range queries in the following way: a range query
q
f
(
A
,
i
,
j
)
on an array
A
=
[
a
1
,
a
2
,
.
.
,
a
n
]
of n elements of some set
S
, denoted
A
[
1
,
n
]
, takes two indices
1
≤
i
≤
j
≤
n
, a function
f
defined over arrays of elements of
S
and outputs
f
(
A
[
i
,
j
]
)
=
f
(
a
i
,
…
,
a
j
)
. This should be done space and time efficient.
Consider for instance
f
=
s
u
m
and
A
[
1
,
n
]
an array of numbers, the range query
s
u
m
(
A
,
i
,
j
)
computes
s
u
m
(
A
[
i
,
j
]
)
=
(
a
i
+
…
+
a
j
)
, for any
1
≤
i
≤
j
≤
n
. These queries may be answered in constant time and using
O
(
n
)
extra space by calculating the sums of the first
i
elements of
A
and storing them into an auxiliary array
B
, such that
B
[
i
]
contains the sum of the first
i
elements of
A
for every
0
≤
i
≤
n
.Therefore any query might be answered by doing
s
u
m
(
A
[
i
,
j
]
)
=
B
[
j
]
−
B
[
i
−
1
]
.
This strategy may be extended for every group operator
f
where the notion of
f
−
1
is well defined and easily computable. Finally notice this solution might be extended for arrays of dimension two with a similar preprocessing.
When the function of interest in a range query is a semigroup operator the notion of
f
−
1
is not always defined, therefore we can not use an analogous strategy to the previous section. Yao showed that there exists an efficient solution for range queries that involve semigroup operators. He proved that for any constant
c
, a preprocessing of time and space
θ
(
c
⋅
n
)
allows to answer range queries on lists where
f
is a semigroup operator in
θ
(
α
c
(
n
)
)
time, where
α
k
is a certain functional inverse of the Ackermann function.
There are some semigroup operators that admit slightly better solutions. For instance when
f
∈
{
max
,
min
}
. Assume
f
=
min
then
min
(
A
[
1..
n
]
)
returns the index of the minimum element of
A
[
1..
n
]
. Then
min
(
A
,
i
,
j
)
denotes the corresponding minimum range query. There are several data structures that allow to answer a range minimum query in
O
(
1
)
time using a preprocessing of time and space
O
(
n
)
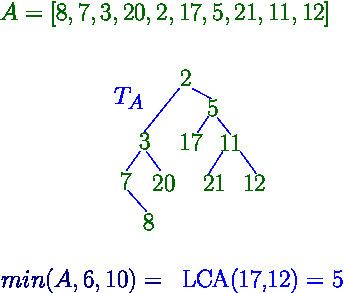
. Probably the simplest solution to sketch here is based on the equivalence between this problem and the Lowest common ancestor problem. We briefly describe this solution.
The cartesian tree
T
A
of an array
A
[
1
,
n
]
has as root
a
i
=
m
i
n
{
a
1
,
a
2
,
…
,
a
n
}
and it has as left and right subtrees the cartesian tree of
A
[
1
,
i
−
1
]
and the cartesian tree of
A
[
i
+
1
,
n
]
respectively. It is easy to see that a range minimum query
m
i
n
(
A
,
i
,
j
)
is the lowest common ancestor in
T
A
of
a
i
and
a
j
. Since the lowest common ancestor is solvable in constant time using a preprocessing of time and space
O
(
n
)
thus so does the range minimum query problem. The solution when f = max is analogous. Cartesian trees can be constructed in linear time.
The mode of an array A is the element that appears the most in A. For instance the mode of
A
=
[
4
,
5
,
6
,
7
,
4
,
]
is 4. In case of ties any of the most frequent elements might be picked as mode. A range mode query consists in preprocessing
A
[
1
,
n
]
such that we can find the mode in any range of
A
[
1
,
n
]
. Several data structures have been devised to solve this problem, we summarize some of the results in the following table.
Recently Jørgensen et al. proved a lower bound on the cell probe model of
Ω
(
log
n
log
(
S
w
/
n
)
)
for any data structure that uses
S
cells.
This particular case is of special interest since finding the median has several applications, for further reference see. On the other hand, the median problem, a special case of the selection problem, is solvable in O(n), by the median of medians algorithm. However its generalization through range median queries is recent. A range median query
m
e
d
i
a
n
(
A
,
i
,
j
)
where A,i and j have the usual meanings returns the median element of
A
[
i
,
j
]
. Equivalently,
m
e
d
i
a
n
(
A
,
i
,
j
)
should return the element of
A
[
i
,
j
]
of rank
j
−
i
2
. Note that range median queries can not be solved by following any of the previous methods discussed above including Yao's approach for semigroup operators.
There have been studied two variants of this problem, the offline version, where all the k queries of interest are given in a batch and we are interested in reduce the total cost and a version where all the preprocessing is done up front and we are interested in optimize the cost of any subsequent single query. Concerning the first variant of the problem recently was proven that can be solved in time
O
(
n
log
k
+
k
log
n
)
and space
O
(
n
log
k
)
. We describe such a solution.
The following pseudo code shows how to find the element of rank
r
in
A
[
i
,
j
]
an unsorted array of distinct elements, to find the range medians we set
r
=
j
−
i
2
.
Procedure rangeMedian partitions A, using A's median, into two arrays A.low and A.high, where the former contains the elements of A that are less than or equal to the median m and the latter the rest of the elements of A. If we know that the number of elements of
A
[
i
,
j
]
that end up in A.low is t and this number is bigger than r then we should keep looking for the element of rank r in A.low else we should look for the element of rank
(
r
−
t
)
in A.high. To find
t
, it is enough to find the maximum index
m
≤
i
−
1
such that
a
m
is in A.low and the maximum index
l
≤
j
such that
a
l
is in A.high. Then
t
=
l
−
m
. The total cost for any query, without considering the partitioning part, is
log
n
since at most
log
n
recursion calls are done and only a constant number of operations are performed in each of them (to get the value of
t
fractional cascading should be used). If a linear algorithm to find the medians is used, the total cost of preprocessing for
k
range median queries is
n
log
k
. Clearly this algorithm can be easily modified to solve the up front version of the problem.
All the problems described above have been studied for higher dimensions as well as their dynamic versions. On the other hand, range queries might be extended to other data structures like trees, such as the level ancestor problem. A similar family of problems are orthogonal range queries also known as counting queries.