
 | ||
In the Unicode standard, a plane is a continuous group of 65,536 (= 216) code points. There are 17 planes, identified by the numbers 0 to 16decimal, which corresponds with the possible values 00–10hexadecimal of the first two positions in six position format (hhhhhh). Plane 0 is the Basic Multilingual Plane (BMP), which contains most commonly-used characters. The higher planes 1 through 16 are called "supplementary planes", or humorously "astral planes". As of Unicode version 9.0, six of the planes have assigned code points (characters), and four are named.
Contents
- Basic Multilingual Plane
- Supplementary Ideographic Plane
- Unassigned planes
- Supplementary Special purpose Plane
- Private Use Area planes
- References
The limit of 17 (which is not a power of 2) is due to the design of UTF-16, which can encode 16 supplementary planes and the BMP, to a maximum value of 0x10FFFF, the last code point in plane 16. The encoding scheme used by UTF-8 was designed with a much larger limit of 231 code points (32,768 planes), and can encode 221 code points (32 planes) even if limited to 4 bytes. Since Unicode limits the code points to the 17 planes that can be encoded by UTF-16, code points above 0x10FFFF are invalid in UTF-8 and UTF-32.
The 17 planes can accommodate 1,114,112 code points. Of these, 2,048 are surrogates, 66 are non-characters, and 137,468 are reserved for private use, leaving 974,530 for public assignment.
Planes are further subdivided into Unicode blocks, which, unlike planes, do not have a fixed size. The 273 blocks defined in Unicode 9.0 cover 24% of the possible code point space, and range in size from a minimum of 16 code points (twelve blocks) to a maximum of 65,536 code points (Supplementary Private Use Area-A and -B, which constitute the entirety of planes 15 and 16). For future usage, ranges of characters have been tentatively mapped out for most known current and ancient writing systems.
Basic Multilingual Plane
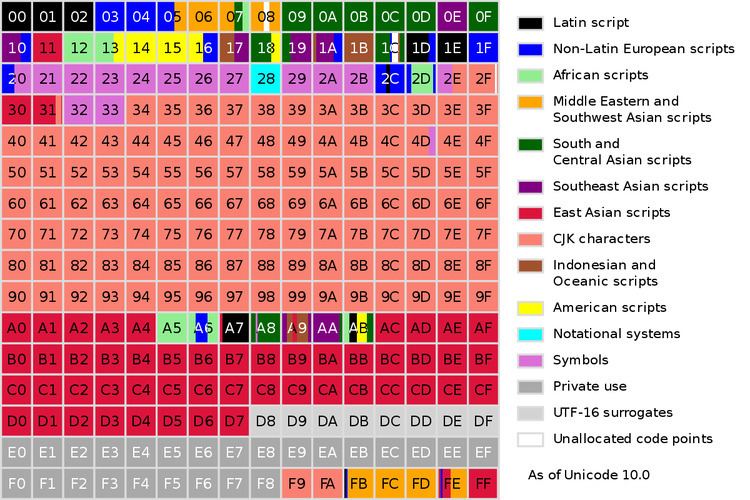
The first plane, plane 0, the Basic Multilingual Plane (BMP) contains characters for almost all modern languages, and a large number of symbols. A primary objective for the BMP is to support the unification of prior character sets as well as characters for writing. Most of the assigned code points in the BMP are used to encode Chinese, Japanese, and Korean (CJK) characters.
The High Surrogates (U+D800–U+DBFF) and Low Surrogate (U+DC00–U+DFFF) codes are reserved for encoding non-BMP characters in UTF-16 by using a pair of 16-bit codes: one High Surrogate and one Low Surrogate. A single surrogate code point will never be assigned a character.
65,408 of the 65,536 code points in this plane have been allocated to a Unicode block, leaving just 128 code points in unallocated ranges (64 code points at 0860..089F, 48 code points at 1C90..1CBF and 16 code points at 2FE0..2FEF).
As of Unicode 9.0, the BMP comprises the following 161 blocks:
Plane 1, the Supplementary Multilingual Plane (SMP), contains historic scripts (except CJK ideographic), and symbols and notation used within certain fields. Scripts include Linear B, Egyptian hieroglyphs, and cuneiform scripts, and also reform orthographies like Shavian and Deseret. Symbols and notations include historic and modern musical notation; mathematical alphanumerics; Emoji and other pictographic sets; and game symbols for playing cards, Mah Jongg, and dominoes.
As of Unicode 9.0, the SMP comprises the following 103 blocks:
Supplementary Ideographic Plane
Plane 2, the Supplementary Ideographic Plane (SIP), is used for CJK Ideographs, mostly CJK Unified Ideographs, that were not included in earlier character encoding standards.
As of Unicode 9.0, the SIP comprises the following five blocks:
Unassigned planes
Planes 3 to 13 (planes 3 to D in hexadecimal): No characters have yet been assigned to Planes 3 through 13. Plane 3 is tentatively named the Tertiary Ideographic Plane (TIP), but as of version 9.0 there are no characters assigned to it. It is reserved for Oracle Bone script, Bronze Script, Small Seal Script, additional CJK unified ideographs, and other historic ideographic scripts.
It is not anticipated that all these planes will be used in the foreseeable future, given the total sizes of the known writing systems left to be encoded. The number of possible symbol characters that could arise outside of the context of writing systems is potentially huge. At the moment, these 11 planes out of 17 are unused.
Supplementary Special-purpose Plane
Plane 14 (E in hexadecimal), the Supplementary Special-purpose Plane (SSP), currently contains non-graphical characters. The first block is for special use tag characters. The other block contains glyph variation selectors to indicate an alternate glyph for a character that cannot be determined by context.
As of Unicode 9.0, the SSP comprises the following two blocks:
Private Use Area planes
The two planes 15 and 16 (planes F and 10 in hexadecimal), are designated as "private use planes". They contain blocks called Supplementary Private Use Area-A (PUA-A) and -B (PUA-B), Private Use Areas, which are available for character assignment by parties outside the ISO and the Unicode Consortium. They are used by fonts internally to refer to auxiliary glyphs, for example, ligatures and building blocks for other glyphs. Such characters will have limited interoperability. Software and fonts that support Unicode will not necessarily support character assignments by other parties.