
Symbol HAND InterPro IPR015194 SUPERFAMILY 1ofc | Pfam PF09110 SCOP 1ofc Pfam structures | |
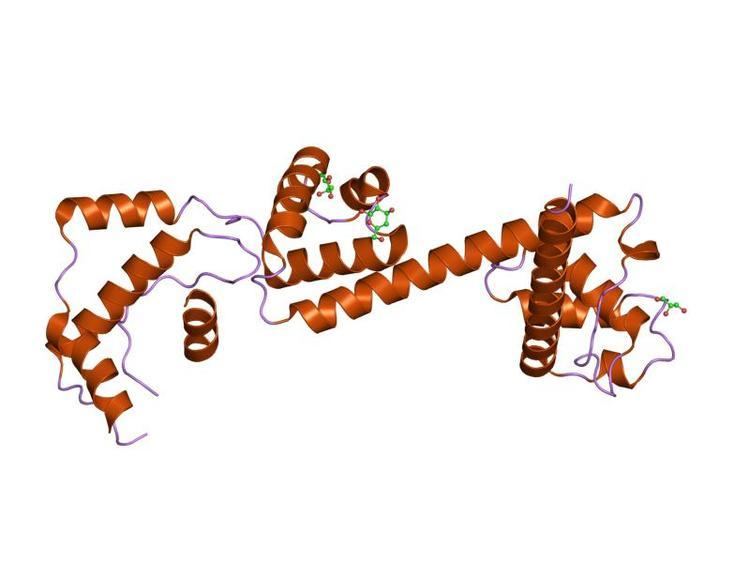 | ||
In molecular biology, the HAND domain is a protein domain which adopts a secondary structure consisting of four alpha helices, three of which (H2, H3, H4) form an L-like configuration. Helix H2 runs antiparallel to helices H3 and H4, packing closely against helix H4, whilst helix H1 reposes in the concave surface formed by these three helices and runs perpendicular to them. This domain confers DNA and nucleosome binding properties to the proteins in which it occurs. It is named the HAND domain because its 4-helical structure resembles an open hand.
HAND domain-containing proteins include proteins involved in nucleosome remodelling, an energy-dependent process that alters histone-DNA interactions within nucleosomes, thereby rendering nucleosomal DNA accessible to regulatory factors. The ATPases involved in nucleosome remodelling belong to the SWI2/SNF2 subfamily of DEAD/H-helicases, which contain a conserved ATPase domain characterised by seven motifs. Proteins within this family differ with regard to domain organisation, their associated proteins and the remodelling complex in which they reside. The ATPase ISWI is a member of this family. ISWI can be divided into two regions: an N-terminal region that contains the SWI2/SNF2 ATPase domain, and a C-terminal region that is responsible for substrate recognition. The C-terminal region contains 12 alpha-helices and can be divided into three domains and a spacer region: a HAND domain, a SANT domain (c-Myb DNA-binding like), a spacer helix, and a SLIDE domain (SANT-like but with several insertions).