
Symbol CHAP Pfam clan CL0125 MEROPS C51 | Pfam PF05257 InterPro IPR007921 Pfam structures | |
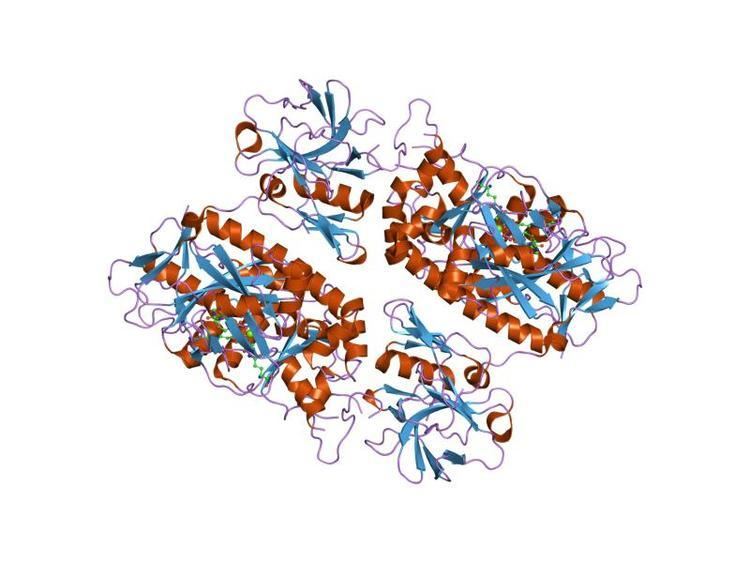 | ||
In molecular biology, the CHAP domain is a region between 110 and 140 amino acids that is found in proteins from bacteria, bacteriophages, archaea and eukaryotes of the Trypanosomidae family. The domain is named after the acronym cysteine, histidine-dependent amidohydrolases/peptidases. Many of these proteins are uncharacterised, but it has been proposed that they may function mainly in peptidoglycan hydrolysis. The CHAP domain is found in a wide range of protein architectures; it is commonly associated with bacterial type SH3 domains and with several families of amidase domains. It has been suggested that CHAP domain containing proteins utilise a catalytic cysteine residue in a nucleophilic-attack mechanism.
The CHAP domain contains two invariant residues, a cysteine and a histidine. These residues form part of the putative active site of CHAP domain containing proteins. Secondary structure predictions show that the CHAP domain belongs to the alpha + beta structural class, with the N-terminal half largely containing predicted alpha helices and the C-terminal half principally composed of predicted beta strands.
Some proteins known to contain a CHAP domain are listed below: